


Your guide to AI: November 2024


Hi everyone!
Welcome to the latest issue of your guide to AI, an editorialized newsletter covering the key developments in AI policy, research, industry, and start-ups over the last month. First up, a few updates:
Thank you to everyone who’s read, shared, and sent us feedback on this year’s State of AI Report. We were overwhelmed by both the volume and thoughtfulness of the reaction. Ultimately, the report is only possible because of the community and we’re very appreciative.
Our publishing schedule has continued unabated, with a new State of AI outtakes series, an evaluation of the state of play in AI-first bio, and our take on why AI isn’t like the dotcom bubble.
It was great to meet so many of our readers at our SF launch event and NYC happy hour. We’ll be in London and Paris before the end of the year and you can subscribe to our events page to ensure you don’t miss any future meet-ups.
Along with events, you can get all of our news, analysis, and events directly in your inbox if you subscribe to Air Street Press.
We love hearing what you’re up to and what’s on your mind, just hit reply or forward to your friends :-)
🌎 The (geo)politics of AI
The White House has issued the first ever National Security Memorandum on AI. This directs government agencies to work on the diversification of the chip supply chain, streamline procurement processes, and to collaborate with international partners. It also doubles down on the AI Research Resource and gives room to bring in more skilled workers from abroad. While none of the memo is revolutionary, it is a reminder that the US still sees AI as a crucial geopolitical battlefield, despite the relative lack of action in the chip wars over the past few months.
No doubt the US security establishment sat bolt upright in response to revelations that the Chinese People’s Liberation Army had developed a model for military use based on Llama. The model was tested on its ability to process military intelligence and offer accurate information for operational decision-making. Meta insists that any use of their models for military purposes violates their terms of service.
Is this proof that open weights models pose a grave risk to the safety of the West? We don’t think so.
As others have pointed out, Llama’s main edge comes from the quality of its training data, not the uniqueness of its architecture. While having Llama out there likely makes the PLA’s job slightly easier, the notion that China, with all of its technical talent, would not be able to build an equivalent pretty easily, isn’t worth taking seriously. Also, as Meta’s Joelle Pineau observed, the PLA finetuned Llama on just 100,000 military dialogue records, and "that's a drop in the ocean compared to most of these models [that] are trained with trillions of tokens so … it really makes me question what do they actually achieve here in terms of different capabilities”.
Meanwhile over on Safety Island, the UK is awaiting the AI Opportunities plan that the new(ish) government commissioned. Expected in the coming weeks, rumored items include visa relaxations, loosened planning restrictions for data center construction, and the creation of a new “AI opportunities unit”. The specifics of any recommendations around government support for compute remain unknown, but given the government’s relaxation of its predecessor's tight spending rules, there should now be some spare GPU money up for grabs.
As AI regulation takes shape around the world, skeptics have often accused big tech companies of regulatory capture. Events took a novel twist this week, with Microsoft accusing Google of using a network of front organizations to undermine their cloud business. They contend that Google is funding groups fronted up by other cloud providers to lobby anti-trust regulators, bolstering its own more direct attacks. Microsoft argues that Google is attempting to “distract from the intense regulatory scrutiny Google is facing around the world by discrediting Microsoft and tilting the regulatory landscape in favor of its cloud services rather than competing on the merits”.
Google doesn’t deny the accusations. Astroturfing is an age-old corporate tactic and isn’t new in the technology industry. It’s been a staple of regulatory fights in the gig economy, for example. The trick is not to get caught.
Anthropic doesn’t need to engage in shady tactics to sound the alarm bell. On Halloween, somewhat ominously, the company called on governments to “urgently take action on AI policy in the next eighteen months” as “the window for proactive risk prevention is closing fast”. They point to improving performance on math, science, and coding benchmarks as a sign that models will soon begin to pose real-world risks. The post plugs Anthropic’s Responsible Scaling Policy, but stops short of saying what measures it thinks governments should actually take - something like SB1047, but not SB1047.
The copyright wars have been a staple of this newsletter and show no sign of dying down. A statement on AI training, organized by Ed Newton-Rex of Fairly Trained, has attracted over 31,000 signatures, including the likes of Björn, John Rutter, Ian Rankin, James Patterson, and Kevin Bacon. The statement simply reads: “The unlicensed use of creative works for training generative AI is a major, unjust threat to the livelihoods of the people behind those works, and must not be permitted.” This comes as Dow Jones, the publisher of the WSJ and New York Post, moved to sue Perplexity for a “massive amount of illegal copying” of their work.
Perplexity hit back claiming that news organizations “prefer to live in a world where publicly reported facts are owned by corporations, and no one can do anything with those publicly reported facts without paying a toll”. Politely, this strikes us as a reach. Copyright exists and you can argue that your interpretation is right and news organizations’ is wrong, but Perplexity’s conspiratorial tone is unhelpful. It also doesn’t tally with Perplexity’s own revenue-sharing program, which it trumpets in the same statement. By their standards, how is this not also “paying a toll”?
We’ve written before about how we think compromise is likely inevitable in this debate between model builders, publishers and content creators. And some people are making it work! Text-to-speech stars ElevenLabs recently revealed that they’d paid out their first $1M to voice actors.
While compromise after much lawfare may be the final destination in the US, we may reach a speedier conclusion in the UK. The government is considering a scheme that would give model builders the right to scrape any content, unless publishers and artists explicitly “opt-out”. Publishers and music rights holders are furious and are demanding an “opt-in”. In practice, “opt-out” option would be a huge win for them, provided the form and process is simple enough. In our piece on copyright and compromise, we outlined a few cases where one side or the other rejected a compromise, only to do worse in the final settlement. Tech companies aren’t the only people who need to learn from history.
🍪 Hardware
While the chip wars continue to rage, it looks like the West and the Chinese Communist Party agree on one thing: neither side wants Chinese companies to use NVIDIA hardware. The Chinese government is ramping up its attempts to dissuade local businesses from buying the sanctions-compliant (but highly capable) NVIDIA H20, in favor of domestic alternatives.
As we covered in this year’s State of AI Report and our essay on Chinese AI, domestic alternatives have so far struggled with reliability and volume, and leading Chinese labs would rather avoid them. The CCP finds itself caught in a bind - simultaneously wanting to produce the world’s best models, while ending its dependence on the foreign hardware needed to do it.
Whatever happens in China, NVIDIA continues to expand on all fronts. In 122 days, the company had a 100k cluster up and running for xAI in Tennessee, with ambitions to double it in size. The secret to moving so quickly? Switching away from its proprietary InfiniBand networking technology to cheaper, Ethernet-based alternatives. You can have a glimpse inside the cluster here.
InfiniBand isn’t on the way out just yet. In fact, it’s gluing together Denmark’s first AI supercomputer, Gefion, powered by 1,528 H100s. Gefion is part of the Danish Center for AI Innovation, funded by the Novo Nordisk Foundation and the Export and Investment Fund of Denmark. The new supercomputer is supporting pilots, pilots the large-scale simulation of quantum computer circuits and a multi-modal genomic foundation model for vaccine design.
A few months ago, we covered how NVIDIA challenger Cerebras was gearing up for an IPO. Despite a spike in good publicity following the launch of a buzzy new inference platform, questions are beginning to mount for the company.
The publication of the company’s Form S1 revealed that almost all of the business’ revenue came from UAE-based G42. This revenue also comes with an option-shaped catch. If G42 makes a single order worth more than $500M but less than $5B before the end of 2025, they will have the right to purchase up to 10% of its value in G42 stock at a discounted rate.
Whatever happens with the existing challengers, it now looks like Sam Altman’s planned multi-trillion dollar chip empire is no more. While the company has made progress on its plans with Broadcom and TSMC to build its first custom chip, it looks like its planned network of foundries has been dropped. Even if it had been possible to raise the vast sums of capital required, the company appears to have concluded that it wasn’t worth the investment in time.
Whoever is providing it, all this compute power needs energy. Microsoft’s move to revive the Three Mile Island nuclear power site looks like the start of a trend. Google unveiled the world’s first corporate agreement to buy the output of small nuclear reactors, while nuclear looks set to become a big theme for private equity. But will this come quickly enough? Three Mile Island won’t be online until 2028, while on optimistic assumptions, small nuclear reactors are unlikely to reach commercial scale before the 2030s. Expect the AI energy squeeze to get worse before it gets better.
🏭 Big tech start-ups
Despite its recent internal struggles, OpenAI continues to grow unabated. The company pulled in $6.6B at an $157B valuation in a funding round led by Thrive Capital. While we’ve become used to mega-rounds in the GenAI era, this is one of the largest ever rounds for a private company and means OpenAI’s valuation is up there with the likes of ByteDance and SpaceX.
OpenAI is now in the process of unpicking the capped-profit model it created when it abandoned its non-profit status in 2019. Under the current model, a non-profit entity oversees a for-profit entity, with early investors returns capped at 100x and later investors at lower numbers. Microsoft, OpenAI’s main benefactor technically holds no equity, but instead gets the first cut of any profits as they start coming in.
This model manages both to be cumbersome and to provide little in the way of oversight. As OpenAI transitions to a for-profit company, both sides’ bankers are gearing up to fight over how equity should be distributed. Check out Matt Levine’s analysis of how these negotiations tend to work and Nathan’s FT op-ed on why OpenAI is right to make the move.
Outside lawyers’ offices and back in the arena, we see the journey from model to product continue unabated. Anthropic, again continues to lead the way, unveiling its computer use feature, along with a bunch of other new features. This allows developers to direct Claude to look at a screen, click buttons, and type text. It’s still in beta and Anthropic acknowledges that it’s error-prone.
The list of early users Anthropic provides - Asana, Canca, DoorDash, Replit, and The Browser Company - provides a clue as to potential use cases.
Again, this is likely a case of a frontier model leader probably putting a bunch of start-ups out of business. However, there is an open question about whether or not an API is the right vehicle for a computer use feature at scale. It’s not hard to see the potential privacy or liability issues stacking up…
Computer use came alongside the launch of Claude 3.5 Haiku and an upgraded version of Sonnet. Anthropic’s own benchmarking shows it edging out GPT-4o across a range of benchmarks, with Haiku a close competitor to 4o-mini. They’ve also thrown in a new agentic tool use stat for good measure.

OpenAI is also getting in on the productizing, with the launch of Canvas, a writing and coding interface. It doesn’t take a particularly forensic examination to notice the similarities between Canvas and Claude Artifacts.
Where the company is differentiating itself is web search. While OpenAI had started integrating links into some queries previously, the new search function comes with a jazzier UX and enhanced reasoning capabilities. To accomplish the latter, OpenAI’s search model is post-trained using new distilled outputs from OpenAI o1-preview. As a nod to the copyright wars, OpenAI is using its newly-minted content partners, as well as existing search engines, as a means of serving up results.
🔬Research
π0: A Vision-Language-Action Flow Model for General Robot Control, Physical Intelligence.
The authors present π0, a robot foundation model that combines a pre-trained vision-language model with flow matching to generate continuous robot actions. The model is trained on over 10,000 hours of demonstration data across 7 different robot configurations and 68 distinct tasks. By using flow matching rather than discrete action tokens, the model can generate precise, high-frequency control signals needed for dexterous manipulation.

The training process involves two phases: pre-training on diverse data to build general capabilities, followed by fine-tuning on specific tasks to achieve mastery. This approach allows the model to learn both broad skills and specialized behaviors while maintaining the ability to recover from mistakes. The model can follow natural language commands and work with high-level language models that break complex tasks into simpler steps.
The researchers evaluated π0 through both zero-shot testing (using only pre-trained capabilities) and fine-tuning experiments on new tasks. The model outperformed existing approaches on dexterous manipulation tasks like folding laundry, assembling boxes, and clearing tables. Zero-shot performance was particularly strong on tasks similar to those in the pre-training data.
However, the work has clear limitations. The researchers note that they don't yet understand which types of pre-training data are most valuable or how much data is needed for reliable performance. The model's success on novel tasks varies significantly, and it remains unclear whether this approach will generalize to substantially different domains like autonomous driving or legged locomotion.
Advancing embodied AI through progress in touch perception, dexterity, and human-robot interaction, Meta.
Meta dropped a bunch of new robotics work in a single release. First up, Sparsh, a general-purpose tactile encoder, provides a versatile, vision-based approach to tactile sensing across different tasks and sensor types, eliminating the need for extensive labeled datasets.
Digit 360, a new fingertip sensor, extends human-like tactile precision to robots. It offers rich multimodal sensory data, capturing intricate surface details and minute forces. This makes it useful in delicate tasks in sectors like healthcare and manufacturing. It’s bolstered by on-device AI that allows responsive processing, with obvious potential uses in robotics, VR, and potentially even prosthetics.

Meta also introduced Digit Plexus, a hardware-software framework that integrates tactile sensors into a unified robotic hand system. This platform coordinates sensory inputs across multiple tactile points, from fingertips to palms, supporting complex hand interactions similar to human touch feedback and motor response.

To smooth human-robot collaboration, Meta also developed PARTNR, a benchmark tool for assessing how AI models perform in collaborative, physical tasks with humans. Built on a simulation platform, PARTNR allows evaluation of large language models in scenarios mimicking household environments.
EMMA: End-to-End Multimodal Model for Autonomous Driving, Waymo.
Introduces EMMA, an end-to-end multimodal model designed for autonomous driving, which leverages a multimodal to process raw camera data and directly produce outputs for various driving tasks. EMMA operates within a unified language space, which represents all inputs and outputs (such as navigation instructions, vehicle states, and planned trajectories) as natural language text. This allows EMMA to apply language processing strengths to tasks traditionally segmented into modules, like perception, motion planning, and road graph estimation, effectively merging these functions for comprehensive task handling.
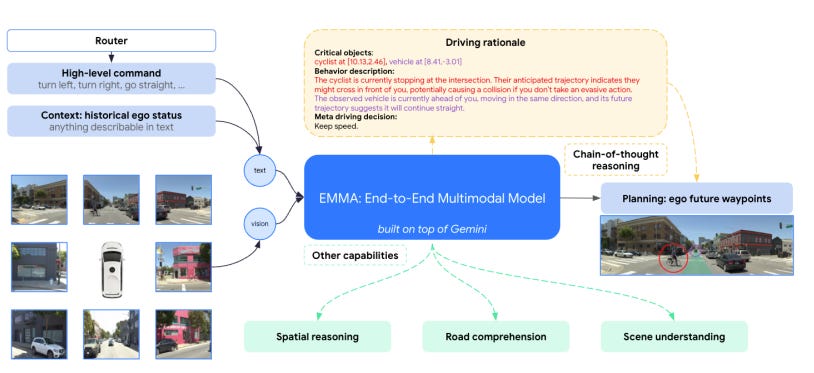
EMMA achieves high performance on public datasets such as nuScenes and the Waymo Open Motion Dataset, particularly excelling in motion planning and 3D object detection using camera inputs alone. A key feature is its "chain-of-thought" reasoning, which enhances decision-making transparency by prompting the model to explain its decisions sequentially, integrating world knowledge. This approach produces outputs such as future vehicle trajectories and object detection estimates in a readable, interpretable format.
While promising, EMMA has limitations: it is constrained to camera-only inputs, lacks fusion with 3D sensing modalities like LiDAR, and requires high computational power, which limits real-world deployment. Despite these, the model shows potential as a generalist framework by achieving competitive results across multiple autonomous driving tasks and efficiently sharing learned knowledge across tasks, outperforming task-specific models.
Also on our radar:
Evaluating feature steering: A case study in mitigating social biases, Anthropic. Investigates "feature steering" - a technique for modifying AI behavior by adjusting interpretable features within Claude 3 Sonnet's neural network. Testing 29 features related to social biases, they found a moderate range where steering could influence outputs without severely degrading performance, and identified a "neutrality" feature that reduced multiple types of bias. However, features often had unexpected "off-target" effects beyond their apparent purpose, and extreme steering impaired model capabilities.
Does Spatial Cognition Emerge in Frontier Models?, Apple. Using a new benchmark called SPACE, the researchers test both large-scale abilities (like mapping environments and finding shortcuts) and small-scale skills (like mental rotation and spatial memory). The results reveal that even advanced AI models perform poorly on many spatial cognition tasks that animals handle well, often scoring near chance level on tests.
Mixture of Parrots: Experts improve memorization more than reasoning, Harvard. Explores the trade-offs between mixture of expert models and standard dense transformers. They demonstrated that MoEs can effectively leverage additional experts to improve memory-intensive tasks like fact retrieval, but find diminishing returns in reasoning tasks like mathematical problem-solving or graph analysis.
Insights from the Inverse: Reconstructing LLM Training Goals Through Inverse RL, Imperial College London, Harvard. Presents a novel approach to understanding how LLMs make decisions by using inverse reinforcement learning to reconstruct their implicit reward functions. On 70M and 410M parameter LLMs, they successfully extracted reward models that could predict human preferences with up to 80.40% accuracy. They then used these IRL-derived reward models to fine-tune new LLMs, finding that the 70M model drove improvements on a toxicity benchmark versus standard RLHF, whereas the 410M resulted in worse performance.
Distinguishing Ignorance from Error in LLM Hallucinations, Technion, Google Research. Distinguishes between two types of LLM hallucinations: those that occur when the model lacks knowledge (HK-) versus when it hallucinates despite having the correct knowledge (HK+). The researchers developed a method called WACK to systematically capture HK+ across models, using techniques like "bad shots" (showing incorrect examples) and "Alice-Bob" (using subtle persuasion) to induce HK+ hallucinations. They found that hallucination types leave distinct signatures in the models' internal states, different models hallucinate in unique ways even with shared knowledge, and that detecting hallucinations works better when using model-specific datasets rather than generic ones.
VibeCheck: Discover and Quantify Qualitative Differences in Large Language Models, UC Berkeley. Proposes VibeCheck, a system that identifies qualitative differences between LLM outputs. It discovers "vibes" (like tone, formatting style, or level of detail) through automated analysis of model outputs and validates each vibe through three criteria: how consistently different judges agree on that vibe, how well it distinguishes between different models' outputs, and whether it predicts user preferences.
💰Startups
🚀 Funding highlight reel
11x, developing autonomous digital workers for enterprise, raised a $50M Series B, led by a16z
Archon Biosciences, using AI to design novel biomolecules, raised a $20M seed, led by Madrona Ventures
Basecamp Research, using the natural world to discover better medicines, raised a $60M Series B, led by Singular
CoreWeave, the GPU compute provider, closed a $650M credit facility, led by Goldman Sachs, JPMorgan, and Morgan Stanley
EvenUp, creating AI-based legal case management solutions, raised a $135M Series D, led by Bain Capital Ventures
Galileo, the AI evaluation and observability platform, raised a $45M Series B, led by Scale Venture Partners
Genie AI, creating an automatic contract drafting platform, raised a $17.8M Series A, led by Khosla Ventures and Google Ventures
Lightmatter, producing 3D-stacked photonic chips, raised a $400M Series D, led by T. Rowe Price
Granola, the AI notetaker, raised a $20M Series A, led by Spark Capital
Nimble, building autonomous warehouses for order fulfillment, raised a $106M Series C, led by FedEx
OpenAI, the frontier AI lab, raised a $6.6B funding round, led by Thrive Capital
Oriole Networks, speeding up data centers for AI, raised a $22M Series A, led by Plural
Poolside, the AI for software engineering, raised a $500M Series B
Reality Defender, a platform for detecting false media content, raised a $33M Series A, led by Illuminate Financial
Sana, building an enterprise AI assistant, raised a $55M venture round, led by New Enterprise Associates
Sierra, the AI customer service agent platform, raised a $175M venture round, led by Greenoaks Capital
Terray Therapeutics, working on small molecule drug discovery, raised a $120M Series B, led by NVentures and Bedford Ridge Capital
Waymo, the self-driving company, raised a $5.6B funding round, led by Alphabet
Wispr, a voice-based personal computing platform, raised a $10M seed round, led by TriplePoint Capital and Neo
Xscape Photonics, building photonic chips for HPC, raised a $44M Series A, led by IAG Capital Partners
🤝 Exits
Applied Intuition, the company building an autonomy stack for self-driving, has acquired the IP portfolio of defunct self-driving start-up Ghost Autonomy
DeepHealth, a portfolio of AI-powered healthcare solutions, has acquired Kheiron Medical, a cancer diagnostics company
Thomson Reuters, the media and content giant, has acquired Materia, a start-up working on AI agents for tax, audit and accounting
Signing off,
Nathan Benaich and Alex Chalmers on 3 November 2024
Air Street Capital | Twitter | LinkedIn | State of AI Report | RAAIS | Events
Air Street Capital invests in AI-first entrepreneurs from the very beginning of your company-building journey.
