


👾 Your guide to AI: March 2023


Hi all!
Welcome to the latest issue of your guide to AI, an editorialized newsletter covering key developments in AI research, industry, geopolitics and startups during February 2023. Before we kick off, a couple of news items from us :-)
We wrote an op-ed for Sifted on how generative AI will change the software landscape and commented for TIME’s cover story on ChatGPT.
On the politics side, we reviewed and recommended spinout policy reform in Tony Blair Institute for Global Change's paper A New National Purpose and were included in Politico’s 20 people who matter in UK technology.
Air Street was featured in Insider’s list of top AI investors 👀
See some of you at London.AI on Thurs 9 March w/DeepMind, Adept, Palantir and Basecamp Research.
Register for our one-day RAAIS conference on research and applied AI 23 June 2023 in London. We’ll be hosting speakers from Meta AI, Cruise, Intercom, Genentech, Northvolt and more to come!
FYI, you might have to read this issue in full online vs. in your inbox.
As usual, we love hearing what you’re up to and what’s on your mind, just hit reply or forward to your friends :-)
🌎 The (geo)politics of AI
Building large-scale AI models requires enormous computing power, which has emerged as the soft power of our time. The US government has realized this ahead of its peers and has passed dozens of laws to better position the country for the future. They’ve introduced incentives for chip companies to avoid trade and IP sharing with Chinese institutions and the Chinese market in general. The latest such rule, which came from the Commerce department, dictates that chipmakers receiving government funds – notably from the CHIPS act – must agree not to expand in the Chinese markets. Unless the Chinese government and companies respond swiftly to the challenge that such rules pose, the country could face an increasing technological lag in AI. We can expect heavy investments in the coming months, like a recent $1.9B investment in memory chips maker Yangtze Memory. There is, however, a more convoluted and gray-zone approach that is being practiced: get supplied through countries that aren’t under American and other Western countries’ sanctions. This is what Russia, which has been hit with a lot more sanctions, is doing. Bloomberg indeed reports that Russian imports of chips from Turkey and the UAE have soared since the Russian invasion in Ukraine. In any case, harder access to the latest NVIDIA GPUs should ensure that the Chinese technological lag will be (at least temporarily) a reality.
The US’s pro-technology policies aren’t just hitting China. In the UK, semiconductor companies are being courted to move their operations to the US to access capital markets and R&D support. The country’s crown jewel, ARM, made headlines this week by confirming it will seek to list in New York and not in London. This sad but unsurprising decision from ARM should be a wake up call for the UK. Lagging R&D funding, uncertainty about access to Horizon, and a lack of strategic focus means that the UK's science leadership is stuck in the domain of rhetoric rather than reality. Considering the UK's deep pool of talent and world-leading universities, it's time policymakers rejected the tyranny of low expectations and placed technology at the heart of a reforming agenda. This should include a reform to university spinout policy to make it permissive to the creation of deeply technical companies and the establishment of a large-scale AI-native computing infrastructure, which could be made available to researchers, startups and larger companies seeking to train AI systems. In fact, such a system could be a compelling compute alternative for AI startups that today raise venture capital to spend on cloud computing. Instead of selling equity dollar-for-dollar to spend on compute, companies could be given dirt cheap access to national AI compute infrastructure. In return, they could offer the government access to the best AI systems, knowledge of how these systems work and where they’re going such that the government gets smarter about policy, utilization and regulation, for example.
The US has been a leader in investments as well as restrictions, but others will follow. Last on record is South Korea, which recently announced it would invest close to $650M in companies working on advanced AI chips. The country has three AI chipmaker candidates that could benefit from the funding: Rebellions, Sapeon Korea and FuriosaAI. But outside of government funding, perhaps a more consequential deal has been struck last December between Korea’s behemoth Samsung electronics and AI software maker NAVER – which developed the 200B-parameter Korean LLM – to develop AI-optimized semiconductor designs.
Back to China: to state the obvious, the country already lags behind the US in LLM research and deployment. The technology behind ChatGPT was developed in the US, and the product itself is a pure American big tech creation. In that regard, the ChatGPT story in China has many fascinating aspects.
Chinese users don’t have direct access to ChatGPT. Most people access it through VPN or by paying external third parties who do have access. Jeffrey Ding, of the ChinAI newsletter, offered a few explanations for why this is the case. First, OpenAI’s services are apparently “considered telecommunications services, restricted under the Chinese government’s Negative List for Foreign Investment.” Second, AI-generated content, especially in the form of eloquent text, is heavily scrutinized because of the role it can play in shaping public opinion. Third, the US itself might want more control over AI products like ChatGPT. And just as China is afraid that ChatGPT can be used to shape public opinion against the CCP agenda, it might not be in the interest of the US to have an easy propaganda tool in the hands of Chinese bad actors (though fixes to ChatGPT misuses work reasonably well).
Beijing told companies not to offer ChatGPT services, but supports firms that want to build a local ChatGPT. According to Nikkei, the government told Tencent Holdings and Ant Group not to offer ChatGPT services to the public, presumably because such services would be difficult to control and censor. Yet, the city of Beijing said it would support companies building a Chinese version of ChatGPT. Obviously, a Chinese version of ChatGPT means a model trained on a lot more Chinese language data than OpenAI’s (though ChatGPT’s Chinese answers are reportedly not too bad!). But more importantly, it means that the largest part of the censorship will come from a ton of reinforcement learning from human feedback (“RLHF”) – just like OpenAI did to make ChatGPT hate fossil fuels. Through RLHF, bias and censorship are indeed very much explicitly introduced in the models.
Motivated by the multiplication of lawsuits against companies using AI to generate new content, we dove last month into methods that are able to detect if a specific image or text were indeed human- or AI-generated. Tests from a TechCrunch journalist showed that although none of the methods was able to systematically classify the output correctly, one of the methods, GPTZero, only made two mistakes on the eight examples it was tested on. This is a very very preliminary study (the test is asymmetric, in the sense that all the output was generated by an LLM, Anthropic’s Claude), but it indicates that existing methods of AI content classification aren’t completely useless and should improve over time. Beware, however, as for any adversarial process, progress in detection capabilities will be inevitably met with progress in detector evasion. The generative whack a mole continues.
🏭 Big tech
We hit the ground running in February with Google releasing a demo of Bard, its competitor to ChatGPT. But instead of being a shining moment for Google’s speed of execution, the demo turned out to be a fiasco, as the chatbot made a factual mistake on the very first example that was displayed. On the same day Alphabet, Google’s parent company, lost $100B in market capitalisation. Yet, factual mistakes like the one Bard did are extremely common in language model outputs – ChatGPT makes a ton of them. So the market panic following Bard’s mistake looks to be more of an indictment of, well, Google’s panic. For a company of Google’s size, playing catchup promises to be challenging. Google had been sitting on a state-of-the-art conversational model called LaMDA for some time now (so long that some of its creators left to launch their own chatbot company, character.ai), and it seems to finally be moving to production. But Bard, for now, remains only a demo.
Meanwhile, Microsoft and OpenAI seem to be moving at breakneck speed. ChatGPT has been integrated into Bing, Microsoft’s search engine. Users can only access it on Microsoft Edge, whose usage surely has grown more than Microsoft ever expected pre-ChatGPT. On Bing, the chatbot refers to itself as Sydney, the same name as a chatbot project Microsoft has been working on for at least six years. According to Microsoft, Bing Chat is faster, more accurate, and more capable than ChatGPT. Notably, it cites its sources; but this doesn’t make it 100% truthful. Neither is it 100% emotionally harmless. It showed a much more cavalier “personality” than ChatGPT, threatening users, maintaining that it’s right when it’s wrong, expressing jealousy, and more rather strange behavior (see thread of examples). But this is changing fast, as engineers seem to continuously fix these problems, via temporary hacks like shortening the number of possible conversation rounds, or in a more sustainable way through updates to the language model itself, via for example adversarial training. Meanwhile, the pricing for Bing Search APIs will increase by 4-5x, which does seem worthy of anti-competitive scrutiny given that several search engine startup competitors including DuckDuckGo make use of the Bing index in their product.
OpenAI released their ChatGPT API. Developers can now integrate the gpt-3.5 turbo model behind ChatGPT into their products. Its price is surprisingly low at $0.002 per 1k tokens, which is 10x cheaper than existing GPT-3.5 models. OpenAI said this is due to better optimizations and achieving a better price/speed/performance tradeoff. This thread from Nathan Labenz gives a good analysis of the price decrease. OpenAI also announced that their ChatGPT API was already used by 4 large early users: Snap, Quizlet, Instacart, and Shop (Shopify’s consumer app). Whisper’s API (OpenAI’s open-source text-to-speech model) was also released. And as an additional sign that OpenAI is working on all fronts, it has set up an alliance with Bain & Company, a prestigious consultancy. Bain will use OpenAI products as part of their core work (employees have access to its APIs) and advise clients on how to best integrate OpenAI products and devise new ones based on enterprise customer needs. This move adds some evidence to the concept that models in themselves are not usable products - they need wrappers, guardrails, workflows just like regular software products. Speaking of enterprise, OpenAI launched an offer dedicated to large ones, where they can among other things have full control over which update of OpenAI’s (or their own finetuned) models to use, the server setups, and the length of inputs to the models (up to 16k). And as time seems to accelerate at OpenAI, Sam Altman (the CEO), wrote an essay titled Planning for AGI and beyond, in which he nudges towards the need for regulatory oversight of large model training and provisioning. Oh, and Andrej Karpathy, star AI researcher, OpenAI alumni, and ex-leader of Tesla Autopilot, has joined OpenAI again.
Another competitor to OpenAI could come from an Amazon/HuggingFace computing alliance. HuggingFace will indeed build the next generation of BLOOM, its open source language model, on AWS servers. The cloud deal is non-exclusive, though. Note that the initial BLOOM model was lauded for its effort in building a multilingual LLM and in being careful about the carbon footprint of training the LLM, but was performance-wise considered inferior to state-of-the-art LLMs.
Meta AI introduced LLaMa, a family of LLMs trained solely on publicly available datasets. According to their paper, LLaMA-13B outperforms GPT-3 (175B) on most benchmarks, and LLaMA65B is competitive with the best models, Chinchilla-70B and PaLM-540B. The fact that LLaMa achieves this using only public datasets is truly remarkable, and researchers will soon be able to examine these models since they can apply for access to the model’s weights and code here. By the time we wrote this newsletter, the weights for LLaMa leaked, amusingly as a torrent in a pull request on LLaMa’s GitHub repo. On the corporate front, Meta is reorganizing its AI teams (again) to increase its pace of building generative AI products.
Also, OpenAI founder Elon Musk wants to build an AI company to rival OpenAI’s “woke AI” and has been approaching and hiring AI researchers. Watch this space.
🍪 Hardware
NVIDIA’s YoY revenue and net income have declined (less than expected), but its datacenters business, including GPUs, seem resilient. We haven’t fully grasped how far the ChatGPT hype will go, and how many companies will try to incorporate AI into their workflows, but if the reality is anywhere close to what companies advertise they will do, NVIDIA’s datacenter business has very bright days ahead. You can read a nice write-up on NVIDIA’s history with AI, from AlexNet in 2012 to OpenAI/Microsoft’s 10K+ GPUs, in this article (including a few comments from Nathan).
Any machine learning model is trained with the goal of ultimately being used thousands/millions/billions of times for inference, concretely for predicting a quantity or generating an object – text, image, video, etc. – given an input. While training a model is usually purely a cost that a company needs to stomach (except when model training is offered as a service, for example for fine tuning on proprietary data), inference is thought of as the phase where one reaps the fruits – the dollars – of the hard GPU labor. But reaping those dollars at Google or Microsoft scale requires a vertiginous amount of other dollars. Continuing on an article last month – where they had analyzed Large Language Models’ (LLMs) training costs – semianalysis.com went in depth on the inference costs of these models. They estimated the cost per query of ChatGPT to be 0.36 cents (for 4k sequence length and 2k tokens per response on average). This is close to Google’s current profit per search query of ~0.55 cents (semianalysis estimation). As a result, integrating a ChatGPT-like model directly into Google search would result in a massive drop in profit – as much as $36B. Of course, this is a very rough estimate (likely too high an upper-bound) which doesn’t account for how modern LLM-powered search would look like. But $2B per market share point in search seems like a worthy prize to figure this out.
Amid geopolitical tensions and shortages, the world seemingly woke up in 2021-2022 to the importance of semiconductors for the world economy and political stability. Investments – and restrictive trade policies – from the West (driven by the US) followed, notably with the CHIPS act. Now that ChatGPT managed to attract the attention of the public and policymakers to years of rapid progress in AI capabilities, will we see massive government-led investment in AI hardware?
And as if to remind us that progress in tech is never linear, news came out from the National Highway Traffic Safety Administration that more than 360,000 Tesla cars equipped with its Full Self Driving assistant will be recalled to fix a flaw in a component of the system. The Autopilot dream has never seemed so distant.
🔬Research
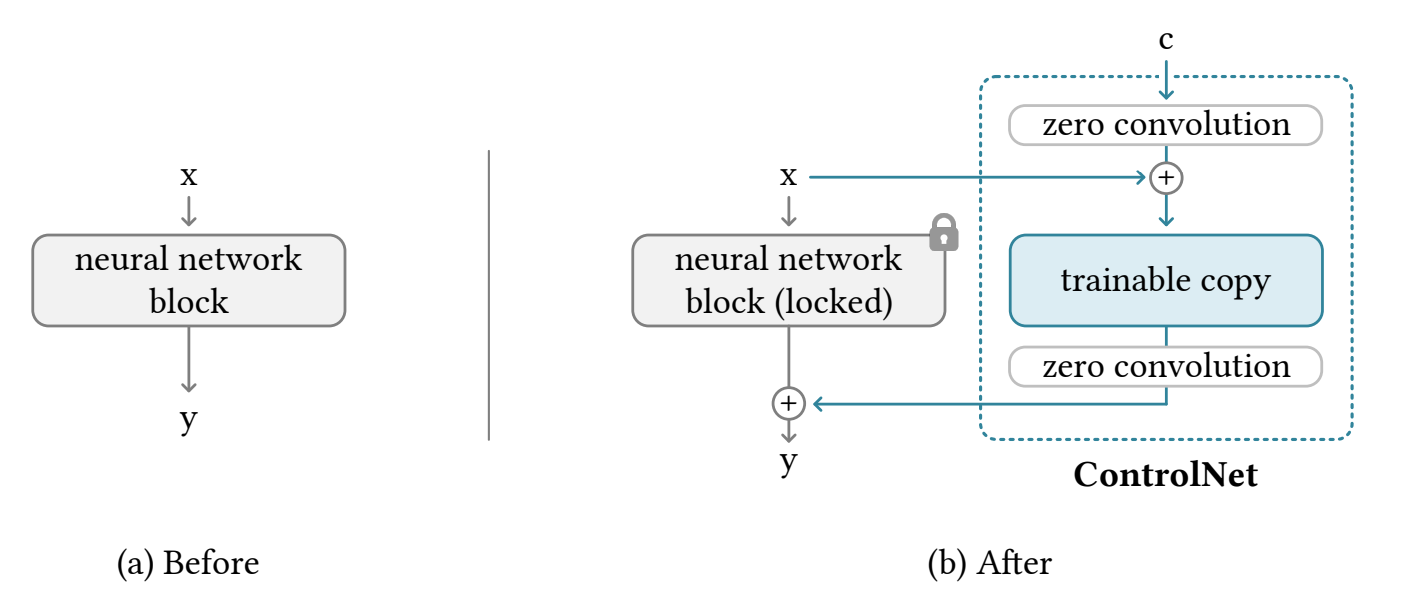
Adding Conditional Control to Text-to-Image Diffusion Models, Stanford. Sampling a desired output from a diffusion model can be challenging. So much so that it has given rise to new jobs – call it prompt engineer, AI whisperer, or more pragmatically a “insanely high-dimensional black box prodder”... To sample from the right region of the conditional distribution, ControlNet proposes a new flexible method that allows the systematic use of an additional input that can better guide the generation of new samples. This can be for example the sketch of an image, a human pose, edge detector data, etc., that the model can use in conjunction with a prompt to generate a desired image. Starting from an initial pre-trained text-to-image model (e.g. Stable Diffusion), the authors freeze the model weights and create a trainable copy of the model (see Image). The additional input (or Condition) is composed with a zero convolution (a 1x1 convolution) and added element-wise to the input. This constitutes the input to the trainable network copy. As a result, in a way that is reminiscent of how a Resnet block would work, the performance of the resulting model should be at least as good as the initial (now freezed) model, and it can only benefit from further fine-tuning thanks to the ControlNet part of the network and the additional input. This thread shows a few impressive examples of ControlNet in action. Relatedly, the following paper uses input videos or a few images along with text to generate new videos: Dreamix: Video Diffusion Models are General Video Editors (Google Research and The Hebrew University of Jerusalem). Samples here.
Toolformer: Language Models Can Teach Themselves to Use Tools, Meta AI Research, Universitat Pompeu Fabra. LLMs can write surprisingly eloquent text, but often struggle to answer factual questions or calculate simple quantities. A simple idea to remedy this is to give LLMs access to external sources of information. For example, in Mind’s Eye, Google researchers trained a model to launch a physics simulation in order to answer physics reasoning questions. In Toolformer, researchers train a model in a self-supervised manner “to decide which APIs to call, when to call them, what arguments to pass, and how to best incorporate the results into future token prediction.” Based on a few demonstrations, Toolformer can use a calculator to answer math questions, a search engine to find a legal text, a translator service, etc. The particularity of this work is that it aims to keep the model as general as possible by training it via self-supervision, which is done by interleaving API calls with regular text. Read and Reap the Rewards: Learning to Play Atari with the Help of Instruction Manuals, Carnegie Mellon University, Ariel University, Microsoft Research. A very different work, but in some ways similar in spirit, to Toolformer is this RL paper which uses external information, in the form of human-written instruction manuals, to improve an RL agent’s game on Atari.
Offline Q-learning on Diverse Multi-Task Data Both Scales And Generalizes, UC Berkeley, Google Research. Offline Q-Learning (in its online form the textbook model-free RL algorithm) could in principle work analogously to self-supervised language and image models: you could train an agent on data so large and heterogeneous that it could generalize to unseen data with minimal finetuning or via smart inference procedures. In practice however, it was challenging to scale models to work well within this classic paradigm. This paper introduces new design choices that overcome these challenges: using a ResNet architecture instead of typical deep RL ones, using a cross-entropy loss instead of mean squared error, and using feature normalization. The resulting models, pretrained on 40 Atari games, verify scaling laws where using a larger model systematically improves performance, and the learned representations are better than other SOTA models, as shown by considerable performance gains when fine-tuning on new unseen games.
Language Is Not All You Need: Aligning Perception with Language Models, Microsoft. The latest multimodal LLM (MLLM) to date comes from Microsoft. Researchers trained their Kosmos-1 (transformer, duh) on text, captioned images, and interleaved text and images. The researchers argue that compared to (text) LLMs, MLLMs have better capabilities in multi-turn multimodal interactions (imagine a discussion with ChatGPT where you can send each other images and discuss them - tbh we were surprised that ChatGPT was not multi-modal already…). The model is trained on large scale text and image datasets like The Pile, Common Crawl, the LAION datasets, and others.
Pretraining Language Models with Human Preferences, University of Sussex, New York University, FAR AI, Northeastern University, Anthropic. To avoid undesired output when generating text from LLMs pretrained on large web-scale text corpora, it has now become standard to use Reinforcement Learning from Human Feedback. The initial pre-training phase optimizes the performance of the model according to the training loss the model was trained to minimize. Using RLHF constitutes a way to operate a trade-off, where we technically achieve a lower performance (higher training loss according to the original metric), but higher conformity to human expectations. This paper tries to find other approaches at the Pareto frontier of alignment and performance (or capabilities). They find that conditional training, which consists in “learning the distribution over tokens conditional on their human preference scores given by a reward model” – in other words incorporating human preferences during pretraining, “reduces undesirable content by up to an order of magnitude [...] while maintaining the downstream task performance”

De novo design of luciferases using deep learning, University of Washington, UCLA, Xi’an Jiaotong University. Luciferases are enzymes that produce light when they oxidize their substrate. They are widely used in bioassays and imaging in biomedical research. But many reasons – notably the fact that there are very few identified native luciferases – explain why we have seen little development in luciferases as molecular probes. This forms a good use case for deep learning-based protein design methods, which are able to generate large numbers of novel proteins with desired folds. The researchers chose which chemicals they wanted the proteins to illuminate. They then used existing methods, including ProteinMPNN, a graph neural network tailored for protein design, to precisely place amino acids that stabilize the enzyme-chemicals reaction. The best-performing luciferase, called LuxSit, sits at 117 residues, and “is smaller than any known luciferase and remains partially folded at 95°C.” A refinement of LuxSit was even “found to be brighter than the natural luciferase found in the bioluminescent sea pansy Renilla reniformis,” one of the few identified natural luciferases. Protein generation and placing active sites are two of the main pain points in enzyme design that deep learning methods promise to consistently overcome. Combined with decades of advances in biotechnology, deep-learning-based protein design has bright days ahead. De novo design of luciferases using deep learning was published in Nature.
💰Startups
Funding highlight reel
We got more details on Character.ai’s latest funding round. The company founded by a team of LLM and chatbot experts and ex-Googlers raised a $200 to $250M funding round led by Andreessen Horowitz that values the company at $1B according to the Financial Times. This comes as Inflection, another star-founder led AI company, which aims to build general computer assistants, is said to be raising around $675M in funding. Recall that both Anthropic and Adept are also in the market for raising significant financing.
Typeface, which was founded by a former Adobe CTO and uses AI to draft marketing text and other content, raised a $65M funding round from Lightspeed Venture Partners, GV (Google Ventures), M12 (Microsoft’s Venture Fund) and Menlo Ventures.
Dutch company Source.ag, which uses machine learning to advise crop growers on the optimal way to maximize their yields, raised a $23M Series A led by Astanor Ventures.
Voicemod, an established startup offering a real time voice changer and modulator, raised a $14.5M funding round from Kfund to take advantage of the latest AI advancements in audio.
Magic, which ambitions to be an alternative to Github Copilot, raised a $23M Series A led by CapitalG. Codium, which concentrates on code integrity via test generation, raised a $10M seed round led by Vine Ventures.
GlossAi, a Tel Aviv-based startup that promises to use AI to turn hours-long videos posted to video streaming websites into shorter engaging snippets, raised a $8M seed round led by New Era Capital Partners.
Fixie.ai raised an undisclosed amount from Zetta Venture Partners, SignalFire, Bloomberg Beta, and Kearny Jackson, and others. The company is building a product around ideas similar to Toolformer (see Research). It wants to build a platform that allows developers to connect LLMs to APIs which increase LLMs capabilities.
Robin AI, a London-based legal technology company with a focus on contract writing, raised a $10.5M Series A led by Plural.
Exits
Music streaming company Tuned Global acquired Stockholm-based AI DJ app, Pacemaker, for an undisclosed sum.
Clarapath, a US company automating the processing of tissue slides in life science research, acquired Crosscope, a computer vision company with a focus on analyzing tissue slides.
GE HealthCare acquired Caption Health, makers of AI-guided software to capture ultrasound images. Note that GE HealthCare’s ultrasound business brought in $3.4B of revenue in 2022.
Daimler’s Torq Robotics, which is focused on autonomous trucking technology, acquired Algolux, a Canadian Series A computer vision company with products in ADAS.
---
Signing off,
Nathan Benaich, Othmane Sebbouh, 5 March 2023
Air Street Capital | Twitter | LinkedIn | State of AI Report | RAAIS | London.AI
Air Street Capital is a venture capital firm investing in AI-first technology and life science companies. We’re an experienced team of investors and founders based in Europe and the US with a shared passion for working with entrepreneurs from the very beginning of their company-building journey.

Excellent as always !
Thank you so much !
I feel your newsletter is getting a strong relevance with the latest public awareness of AI progress.
One comment :
Don’t you think it could be worthwhile to add a specific section on AI-safety/AI-alignement articles/events ?
these updates are amazing, very excited to see what the future holds. A lot of companies are utilizing generative AI