
☀️ Your guide to AI: June 2024


Prefer the audio version? Listen to it here
Hi everyone!
Welcome to the latest issue of your guide to AI, an editorialized newsletter covering the key developments in AI policy, research, industry, and startups over the last month. But first, some news!
It’s your last chance to register for our annual Research and Applied AI Summit (RAAIS) on 14 June, which brings together 200 AI researchers, engineers, founders, and operators from around the world for a day of best practices. We’ll feature talks from Synthesia, Altos Labs, Recursion Pharmaceuticals, Vercel, InstaDeep, Wayve, and V7.
Thank you to the hundreds of researchers, builders, and operators who came to our meet-ups in SF, NYC and Paris. Keep an eye on our events page for future meet-ups.
Don’t forget to subscribe to Air Street Press to receive all our news, analysis and events directly in your inbox. Recent pieces have included an update on European defense readiness, reflections on hype cycles in tech, and our thesis on where the AI hardware market is headed.
Listen back to Nathan’s recent opening talk at MIT Tech Review’s EmTech conference, which covers the major themes in recent AI research and how to evaluate promising ideas.
We’re releasing more and more of our content in audio form for those of you who listen on the go, or multi-thread modalities :-), including this newsletter - check it out on Spotify here.
We love hearing what you’re up to and what’s on your mind, just hit reply or forward to your friends :-)
🌎 The (geo)politics of AI
May saw the second AI Safety Summit, hosted in Seoul. This event brought together representatives from the US, France, UK, China, as well as the leading frontier AI labs. The summit produced two statements (neither signed by China) around the importance of advancing interoperable AI governance frameworks and improving safety and inclusivity. Meanwhile, the labs attending signed up to a fresh set of non-binding Frontier AI Safety Commitments, which expressed support for transparency requirements and committed them to certain steps around risk assessment and management.
On the one hand, this kind of engagement is welcome, but on the other, much of this work feels like a replication of the much-vaunted Bletchley Declaration of November last year. Anyone involved in a start-up knows a non-binding letter of interest from a customer doesn’t mean anything - why should these non-binding commitments mean anything more? There are already signs these companies aren’t playing ball. Both the lack of any real movement and the fact that the near final text of the main statement leaked to Politico before the summit had even started makes one question how good a use of everyone’s time these set piece occasions really are…
One of the outputs of last year’s Safety Summit was the decision to commission Yoshua Bengio and a panel of scientists to produce a report on AI risks and potential mitigation. An interim version dropped this month, listing out a range of risks (notably not extinction) and highlighting the strong disagreements between scientists on the current and future capabilities of future systems and the trajectory of development. Unsurprising.
Normally an international summit would be the leading safety item for us, but compared to recent events at OpenAI, it seemed like something of a sideshow. It’s been a challenging few weeks for the company in the public eye. Not only did a product launch go off-the-rails (more on that later), but we saw two high-profile departures. Co-founder Ilya Sustkever was the first to (officially now) go, while superalignment lead Jan Leike jumped ship for Anthropic. A number of researchers working on safety-related questions also left the company.
On one level, this isn’t surprising. After all, it’s hard to come back from trying to oust your co-founder. These departures combined with last year’s events reflect an increasingly irreconcilable split that’s been playing out at OpenAI. In crude terms, we saw Altman, much of the engineering team, and OpenAI’s Microsoft benefactors, pushing to go bigger and faster. Meanwhile, we had Ilya, the former board, and a number of people working on safety trying to apply the brakes. There was only so long these two sides could live under the same roof.
To add insult to injury, the departures came with two kickers. Firstly, the revelation that OpenAI attempted to tie up its ex-staff with unusually restrictive NDAs. Departing employees had a choice between forgoing their right to criticize their former employer in perpetuity or foregoing their vested equity. Following criticism by reporters who dug into the matter and many on X who piled on, the company apologized and dropped the terms.
Secondly, former board member Helen Toner re-emerged to criticize Altman and the company for a culture of secrecy, claiming that the Board had first learned of ChatGPT from X/Twitter. She also co-wrote a piece with former colleague Tasha McCauley arguing that their experiences of the company highlighted the shortcomings of self-regulation. The company has announced a new Safety and Security Committee, featuring board members and outside participants to make recommendations in the next 90 days on critical safety and security decisions.
We aren’t well-placed to adjudicate intra-OpenAI beef (nor do we have much interest in doing so), but none of the above is that surprising (again). A few years ago, many of these research labs were small, obscure teams whose work was sufficiently esoteric for those on the outside that they didn’t have to grapple with questions around deployment or commercialization. Seemingly overnight, they’ve become multi-billion dollar enterprises at the center of a global power struggle at warp speed for AI supremacy and economic growth. It’s unsurprising this has now manifested as a culture shock. After all, as the current Google AI search result kerfuffle is demonstrating, even experienced incumbents can get these things wrong… Generative AI products are not a walk in the park. But at the same time, with governments and regulators everywhere watching closely, labs don’t have the luxury of time to adjust.
We’re getting a glimpse of this future in California, as the state gears up to pass the snappily named Safe and Secure Innovation for Frontier Artificial Intelligence Models Act, or SB-1047. The bill, which is the product of heavy lobbying by the x-riskers at Center for AI Safety (who have previously called for models that exceed 70 on MMLU to be banned), is a textbook example of how a focus on narrowly-defined safety can be destructive for competition.
Eccentrically, the bill covers any model that “was trained using a quantity of computing power sufficiently large that it could reasonably be expected to have similar or greater performance as an artificial intelligence model trained using a quantity of computing power greater than 10^26 integer of floating point operations in 2024”. This should immediately ring alarm bells. Compute and performance are not the same thing and as Rohan Pandey of ReworkdAI has argued, it could easily result in the threshold being set arbitrarily low if someone releases a suboptimally trained model. There can be good reasons for suboptimal models (e.g. Llama 3, so it could be deployed on easily available hardware) or bad ones (e.g. a big tech company deliberately inflicting low thresholds on competitors).
Secondly, the bill poses a serious threat to open source. Despite the bill containing provisions for a new advisory council to advocate for open source, any covered model will need a remote kill switch and the ability to delete all copies and derivations. This is essentially impossible with any open source model in existence today and would require a degree of control, monitoring, and surveillance that the community would rightly find unacceptable and infeasible.
This is a good reminder that the seemingly evenly matched safety debate on X/Twitter doesn’t reflect behind-the-scenes activity. In the real world, one side has done a significantly better job at engaging and persuading policymakers. If the community doesn’t want legislation like this to become the norm, it’ll need to organize better and, as we’ve often advocated, faster.
🍪 Hardware
The NVIDIA bandwagon shows no sign of slowing down, as the company published healthy Q1 results, smashing already high market expectations. Quarterly revenue hit $26B, up 18% on the last quarter and 262% year-on-year, while its data center revenue jumped 427%. The company also announced an increase to its dividend and a planned 10-1 stock split. This stands in contrast to its primary rivals, AMD and Intel, who both posted underwhelming earnings in April.
If demand for AI hardware continues in its current form (e.g. high-powered hardware, primarily via data centers), it’s hard to see NVIDIA’s rivals closing the gap. Not only does it produce the most performant hardware, none of its rivals come close to competing with its networking capabilities, which navigate the high bandwidth and low latency needed for AI workloads. As we can see from earnings, NVIDIA is struggling to meet demand, while AMD’s demand is lagging supply. Tenders also suggest that NVIDIA is likely to be the prime beneficiary of the government GPU trade that’s taking off. The only potential chink in the company’s armor might be around a future shift to smaller, locally-hosted models, which can draw on the kinds of cheaper hardware NVIDIA hasn’t customarily made. We have a longer take on NVIDIA’s history, the bets it has made (often against the appeal of Wall Street) and why it is so powerful here.
Meanwhile, the AI chip world could soon see a new entrant, in the form of SoftBank Group’s Arm. The company has announced that it will develop AI chips, with the first products launching in 2025. While Arm’s IP is ubiquitous in the chips that power mobile phones, the company’s attempts to break into the AI chip world have so far disappointed. The company’s instruction set architecture is not as well-suited for the parallel processing required for AI training and inference, its software ecosystem is less mature, and it’s struggled against well-entrenched competition in the data center where GPUs are king. A specialized chip design might resolve the first issue, but the latter two will remain a formidable challenge.
There is one bright spot for Arm, however, which is the emerging ‘AI PC’ market. NVIDIA is rumored to be in talks with Arm about a PC chip that pairs Arm cores with the Blackwell GPU architecture. The company has already teamed up with Microsoft on its CoPilot+ PCs, the brand name the company has given to laptops optimized for AI features. These are powered by Qualcomm’s Arm-compatible ‘Neural Processing Units’. This market may prove better suited to Arm’s core strengths, rather than doing battle in the cloud.
🏭 Big tech start-ups
Elon Musk’s xAI announced that it had completed an eye-watering $6B Series B round, valuing the company at $24B. It’s likely that this funding round will primarily be used to pay its equally eye-watering GPU bills - the company is said to be in discussions with Oracle (which builds and runs GPU data centers) about a $10B cloud services deal. While the company has demonstrated an ability to roll-out high-performing models at pace with a small (crack) team (as they say), from a standing start, we’re no closer to figuring out what its long-term ambitions are. At various stages, xAI’s stated goals have been ‘maximal truth-seeking’, powering X, and preventing ‘AI dystopia’. Not only do all three of these arguably conflict, it’s not obvious that the company is trying to accomplish any of them. We await future developments with interest.
It was a big month for OpenAI, as it unveiled GPT-4o (for “omni”), billed as the company’s flagship model, with the ability to reason across audio, vision, and text in real-time and with personality. The previous ChatGPT Voice Mode combined three separate models, which transcribed the audio to text, processed it, and converted the text back to audio. This lacked the ability to judge tone or expression and introduced additional latency. By contrast, GPT-4o combines all these modalities in a single end-to-end model (adding another chapter of the Bitter Lesson). This model was able to hit GPT-4 Turbo level performance for text, reasoning, and coding, while exceeding it on multilingual, audio, and vision capabilities.

Unfortunately, everyone’s collective attention was quickly sidetracked by one of the more bizarre rows of the GenAI era, as Scarlett Johansson called out the company’s use of a voice that sounded “eerily similar” to her own for the demo. She said that OpenAI had previously approached her to voice ChatGPT’s voice capabilities and that she had declined. OpenAI claimed that they had cast the voice of ‘Sky’ before approaching Johansson and the documentary record appears to back them up.
Putting aside the issue of whether a voice can be legally protected (in fact, prior cases in US courts ruled that a person’s voice cannot be copyrighted), this dispute illustrates the challenges that lie ahead for model builders. While there are some clear cut cases (e.g. Getty Image watermarks appearing on images generated by Stable Diffusion), there are plenty of more ambiguous examples (the OpenAI/New York Times litigation being a good case). It’s easy to imagine there being more and more false alarms, hence why OpenAI seems keen to head as many of its potential foes off at the pass as possible.
Meanwhile, we’ve seen a run of Gemini updates from Google DeepMind. As well as Gemini getting a strong billing at Google I/O, there were some technical updates. The company unveiled Gemini 1.5 Flash, a lightweight model optimized for speed and efficiency, with impressive multimodal reasoning capabilities and a 1 million token context window. Gemini 1.5 Pro has also been enhanced and given a 2 million token window. We also now have an updated Gemini 1.5 technical report, which signals a significant improvement in capabilities since just February.

Outside the immediate Gemini family, Google also unveiled Gemma 2, the latest in their line of lightweight open source models and PaliGemma, a new open vision-language model. Similar to CLIP, PaliGemma combines SigLIP-So400m, a state-of-the-art-model that can understand images and text, as the image encoder and Gemma-2B as the text decoder. Pre-trained on image and text data, it can be fine-tuned for specific use cases, including image captioning, visual question answering, and document understanding.

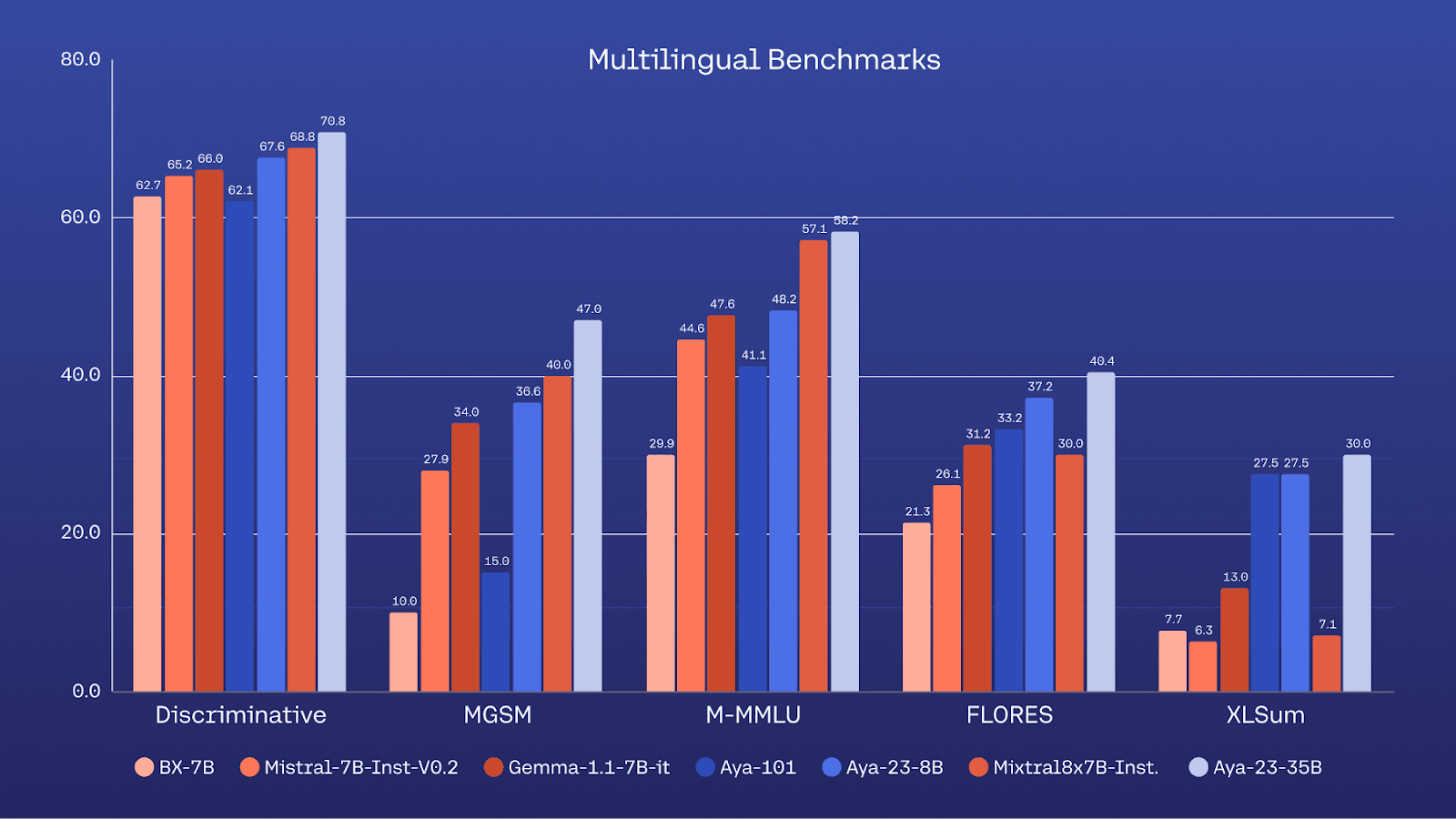
Speaking of open source, Cohere for AI, its namesake’s not-for-profit research lab, announced the release of Aya 23, a new family of multilingual LLMs covering 23 different languages. This is the product of the organization’s Aya initiative, which brought together 3,000 researchers from around the world to build a multilingual finetuning dataset and model. This follows on from Cohere for AI’s Aya 191, which had covered 101 languages, with an emphasis on breadth over depth. Aya 23 is available in 8B and 35B sizes with open weights and scores highly versus peers across a range of multilingual benchmarks.
Meanwhile, Mistral had two strokes of good fortune. Firstly, the UK Competition and Markets Authority announced that it was dropping its investigation into the company’s Microsoft investment … one day after formally opening it. This followed weeks of unnecessary uncertainty, likely wasted lawyers fees from Mistral, and will have consumed resources at an already stretched regulator - all for the sake of a small non-equity investment.
Secondly, the company hired its first US general manager as it prepares to expand across the Atlantic. The company is betting that enterprise customers will want cheaper, open alternatives to Google and OpenAI that don’t lock them into wider ecosystems. This will be an important test case for the ability of European foundation model providers to be taken seriously on the global stage. We wish the Mistral team luck and will be watching closely.
🔬Research
Accurate structure prediction of biomolecular interactions with AlphaFold 3, Google DeepMind and Isomorphic Labs.
Introduces AlphaFold 3 (AF3), the latest iteration of Google DeepMind’s protein structure prediction model. Unlike its predecessors, AlphaFold 1 and 2, AF3 goes beyond protein structure prediction to predict the structures of a wider range of biomolecules such as nucleic acids, small molecules, ions, and modified residues. This updated model demonstrates significantly improved accuracy over specialized tools in predicting protein-ligand, protein-nucleic acid, and antibody-antigen interactions, showcasing its potential for broad application in biological and therapeutic research.

AF3 introduces several changes to improve its predictions. It simplifies the way it processes data, reducing the need for complex sequence alignments, instead using a new Pairformer Module, which focuses on how pairs of molecules interact. Additionally, it uses a Diffusion Module that directly predicts the positions of atoms without relying on complicated geometric frames. This makes the model more flexible and able to handle various chemical structures more efficiently.
To prevent the model from generating plausible but incorrect structures, AF3 uses cross-distillation. This involves training the model with examples from a related version, AlphaFold-Multimer, which helps it learn to avoid common mistakes. AF3 also includes a method for assessing the confidence of its predictions, ensuring more reliable results.
The Foundation Model Transparency Index v1.1, Stanford University.
Conducted in May 2024 the latest installment of the index assessed the transparency of 14 leading foundation model developers based on 100 indicators spanning ‘upstream’ factors data, labor, compute, ‘model-level’ factors around capabilities and risk, ‘downstream’ criteria around distribution, and societal impact.
Compared to the initial index from October 2023 (v1.0), average scores improved from 37 to 58 out of 100, with developers disclosing new information for an average of 16.6 indicators. However, significant gaps in transparency remain, especially regarding upstream resources like data and labor.
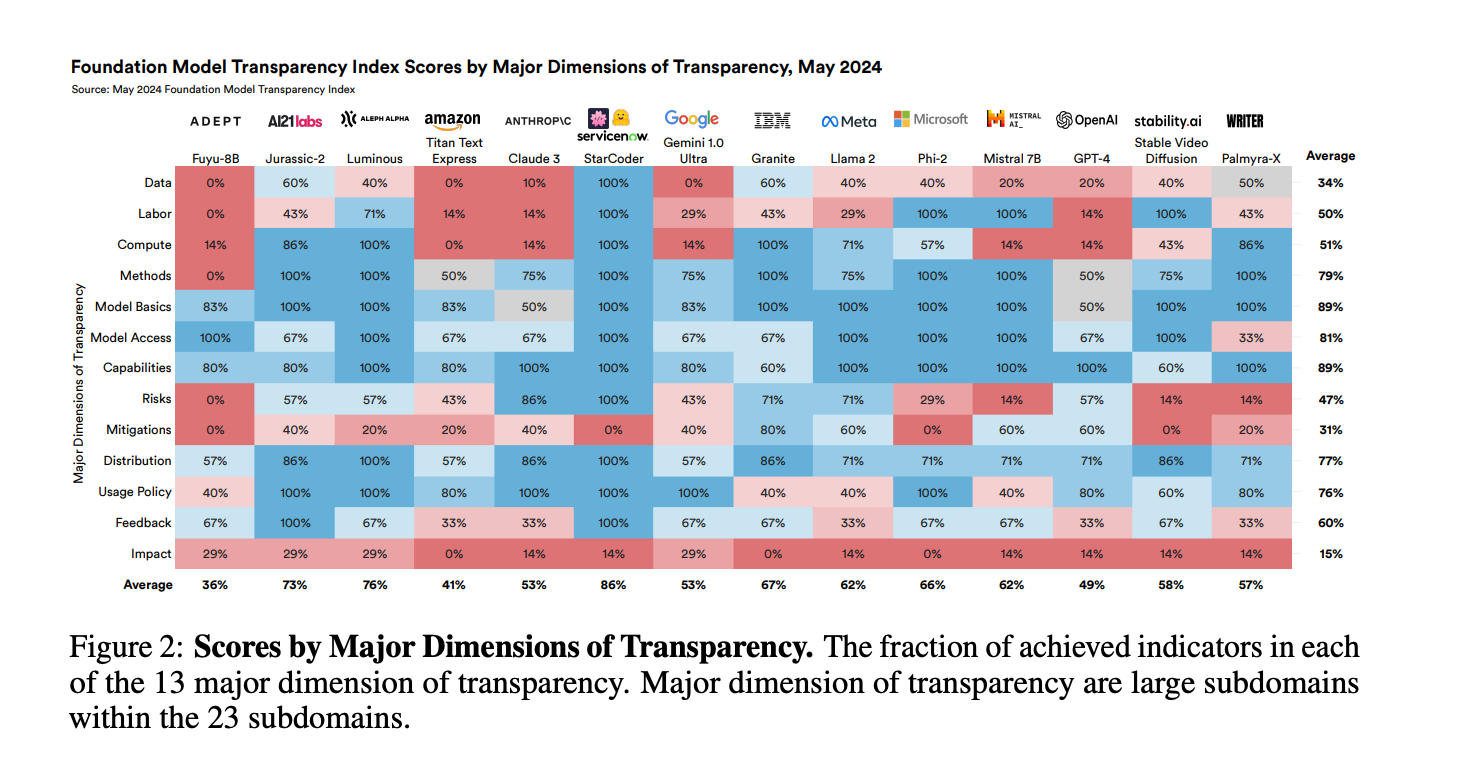
The index found wide variation in transparency among developers, with scores ranging from 33 to 85. Open source model developers generally outperformed closed source developers, especially on upstream indicators. Overall, developers scored highest on user interface, model capabilities, and model basics, but struggled with data access, societal impact, and demonstrating model trustworthiness. Several subdomains like compute and usage policies saw marked improvements since v1.0. Of the major labs, Meta scored highest at 60 (up from 54 in October) and Amazon lowest at 41 (up from 12 in October).
The report recommends that foundation model developers publish transparency reports, customers exert influence to drive transparency, and policymakers assess interventions in persistently opaque areas. We think that’s fair and will accelerate progress.
MobileCLIP: Fast Image-Text Models through Multi-Modal Reinforced Training, Apple.
Introduces MobileCLIP, a new family of efficient image-text models optimized for fast inference on mobile devices, prioritizing low latency and small model size. The authors introduce a novel training approach called multi-modal reinforced training, which improves the accuracy of these compact models by transferring knowledge from an image captioning model and an ensemble of strong CLIP encoders. This additional knowledge, including synthetic captions and embeddings from the teacher models, is stored in a reinforced dataset, avoiding additional computational overhead during training.

The family includes four variants (S0, S1, S2, and B), catering to different latency and size requirements for varying mobile applications. MobileCLIP models trained on the reinforced dataset achieve state-of-the-art latency-accuracy tradeoffs for zero-shot classification and retrieval tasks, outperforming larger CLIP models. For example, the MobileCLIP-S2 variant is 2.3 times faster while being more accurate than the previous best CLIP model based on ViT-B/16.
The authors demonstrate the effectiveness of their multi-modal reinforced training by applying it to a CLIP model based on the ViT-B/16 image backbone, resulting in a significant average performance improvement on 38 evaluation benchmarks compared to the previous best model. Moreover, they show that their approach achieves 10 to 1000 times better learning efficiency than non-reinforced CLIP training.
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet, Anthropic.
Eight months ago, Anthropic's interpretability team began scaling sparse autoencoders to extract monosemantic features from their Claude 3 Sonnet model. A sparse autoencoder is a neural network used to learn efficient representations of data by emphasizing important features and ensuring only a few features are active at any time. It consists of an encoder, which maps input data to a higher-dimensional space, and a decoder, which attempts to reconstruct the original data from these sparse features. By using SAEs, the team could decompose the activations of Claude 3 Sonnet into interpretable components.
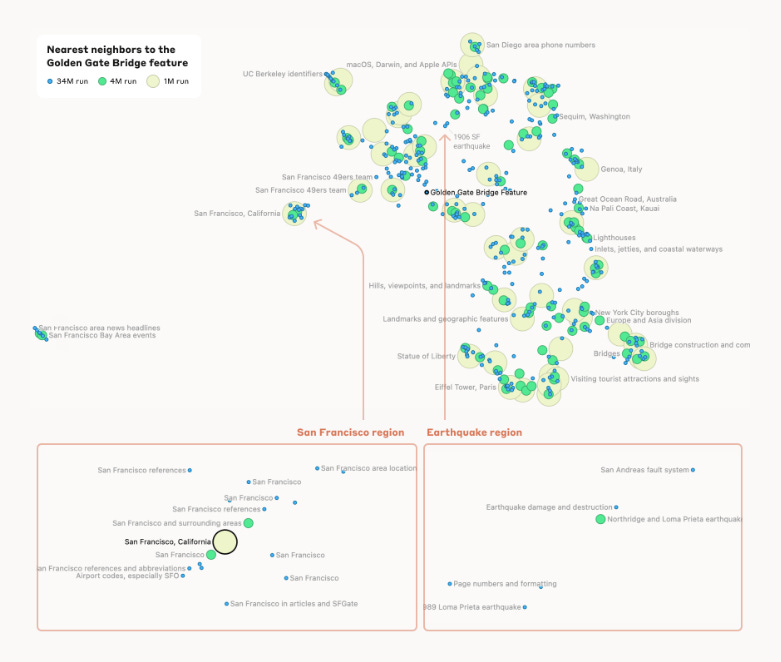
Initially, the feasibility of this approach for state-of-the-art transformers was uncertain. However, the team successfully scaled the method, extracting high-quality, interpretable features. These features were diverse and highly abstract, capable of responding to and influencing abstract behaviors. Examples included features representing famous people, locations, and type signatures in code. Some features exhibited multilingual and multimodal properties, reflecting the same concept across different languages and media.
The team found features that could have safety implications. These included features related to security vulnerabilities, biases, deception, and dangerous content such as bioweapons. Although these features indicate potential safety risks, their presence does not confirm the model's ability to execute harmful actions.
Also on our radar:
De novo antibody design with SE(3) diffusion, Exscientia. Introduces IgDiff, a new model for designing antibody structures. They train this model on a large dataset of antibody structures and show that it can generate realistic and diverse new antibodies. The generated antibodies have similar structural properties to natural antibodies and are predicted to fold properly when their sequences are determined. The authors also demonstrate that IgDiff can be used for various antibody engineering tasks, such as designing the key binding regions or pairing light and heavy chains.
The future of rapid and automated single-cell data analysis using reference mapping, Helmholtz Center Munich, Wellcome Sanger Institute, New York University. A perspective article that discusses the potential of single-cell reference mapping to revolutionize the analysis of single-cell sequencing data. By aligning new datasets to well-annotated reference atlases, researchers can automate cell type identification, study disease states, and integrate data across modalities and species. The authors explore applications, including mapping disease samples to healthy references, constructing perturbation atlases, cross-modality mapping, and cross-species comparisons.
Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models, KAIST AI, LG AI Research, Carnegie Mellon University. Introduce Prometheus 2, an open-source language model designed to provide evaluations of other language models. By merging models trained separately on direct assessment and pairwise ranking, it’s able to closely mirror human and GPT-4 judgments across both evaluation formats. Experiments show that Prometheus 2 achieves state-of-the-art performance in correlating with human evaluators and proprietary language models on several benchmarks. This is particularly useful for the automated evaluation and improvement of smaller language models.
BiomedParse: a biomedical foundation model for image parsing of everything everywhere all at once, Microsoft Research. Introduces BiomedParse, a comprehensive biomedical foundation model, designed to enhance image analysis by simultaneously performing segmentation, detection, and recognition tasks for 82 object types across nine imaging modalities. Unlike traditional methods that handle these tasks separately and often require pre-specified spatial inputs like bounding boxes, BiomedParse uses joint learning to improve accuracy and efficiency, leveraging natural language prompts to identify and segment objects. The model's robustness is further enhanced by using GPT-4 to harmonize text descriptions with biomedical ontologies.
Neural Scaling Laws for Embodied AI, MIT, TUM Munich. By analyzing 198 research papers, a metaanalysis confirms that scaling laws apply to both RFMs and LLMs in robotics, with performance consistently improving as compute, model size, and training data increase. The power law coefficients for RFMs are found to be similar to those in computer vision and outperform those for LLMs in the language domain. The study also highlights variations in these coefficients based on task complexity and the emergence of new capabilities as models scale.
Thermodynamic Natural Gradient Descent, Normal Computing. Introduces a new algorithm called Thermodynamic Natural Gradient Descent (TNGD) for training neural networks. TNGD combines the power of GPUs for computing gradients and curvature information with the efficiency of analog thermodynamic computers for solving linear systems. The authors show that TNGD can achieve comparable efficiency to first-order optimization methods, while TNGD performs well on classification and question-answering tasks. This suggests the possibility of leveraging specialized analog hardware to greatly reduce the computational overhead of second-order optimization methods, making them more practical for training large-scale AI models.
The AI Community Building the Future? A Quantitative Analysis of Development Activity on Hugging Face Hub, Oxford Internet Institute, Alan Turing Institute. Presents a quantitative analysis of usage patterns on Hugging Face. They find that activity across model, dataset, and application repositories is highly skewed, with 70% of models having never been downloaded, while 1% of models (primarily developed by big tech companies) account for 99%. They find that a core group of developers are highly active, while 89% work alone. This is unsurprising (as is often the case on marketplaces of various kinds) but nice to see quantified.
Diffusion for World Modeling: Visual Details Matter in Atari, University of Edinburgh, University of Geneva, Microsoft Research. Introduces DIAMOND, a novel reinforcement learning agent that learns to play Ataria games within a diffusion-based world model. The authors demonstrate that careful design choices, such as using the EDM diffusion formulation and an appropriate number of denoising steps, are crucial for making the diffusion world model stable and efficient over long time horizons. DIAMOND achieves state-of-the-art performance among world model-based agents on the challenging Atari 100k benchmark.
🍷 FineWeb: decanting the web for the finest text data at scale, HuggingFace. The fine folks at HF recently created and open sourced a web-scale dataset for LLM training called FineWeb. In this article, they walk through their stepwise approach to doing so, the results of their ablations for each of the design choices they considered, and the libraries they used to solve problems like scaling dataset cleaning across thousands of CPUs. I wrote a thread here on the fun parts of the piece.
💰Startups
🚀 Funding highlight reel
Carbon Robotics, the precision agriculture company, raised an $85M Series C, led by NVentures.
Coreweave, the GPU data center and cloud provider, agreed a $7.5B debt financing facility, led by Blackstone and Magnetar.
DeepL, the AI-powered translation company, raised a $300M Series C, led by Index Ventures.
EthonAI, using AI to find product defects, raised a $16.5M Series A, led by Index Ventures.
H Company (formerly known as Holistic), a new foundation model builder focused on task automation, raised a $220M seed, led by Accel.
LabGenius, the protein therapeutics company, raised a $45 Series B, led by M Ventures.
Leya, the AI lawyer assistant focused on Europe, raised a $10.5M seed, led by Benchmark.
Nabla Bio, working on generating antibody drugs, raised a $26M Series A, led by Radical Ventures.
Overland AI, working on off-road vehicle autonomy, raised a $10M seed, led by Point72 Ventures.
Patronus AI, working on LLM error detection for enterprise, raised a $17M Series A, led by Notable Capital.
PolyAI, building voice assistants for customer service, raised a $50M Series C, led by Hedosophia.
Praktika, creating AI avatars for language learning, raised a $35.5M Series A, led by Blossom Capital.
Rad AI, the AI-powered radiology reporting start-up, raised a $50M Series B, led by Khosla Ventures.
Scale AI, the data creation platform for AI, raised a $1B Series F, led by Accel.
SmarterDx, an AI hospital billing platform, raised a $50M Series B, led by Transformation Capital.
Suno, the music generation start-up, raised a $125M Series B, led by Lightspeed.
Triomics, using GenAI to streamline cancer trial enrollment, raised a $15M Series A, led by Lightspeed.
Wayve, building the foundation model for self-driving, raised a $1.05B Series C, led by SoftBank Group.
WEKA, the AI and cloud data platform, raised a $140M Series E, led by Valor Equity Partners.
xAI, the foundation model builder, raised a $6B Series B, with participation from Valor Equity Partners, Vy Capital, a16z, Sequoia, and others.
ZeroMark, building an AI-powered auto-aiming system for rifles, raised a $7M seed, led by a16z.
🤝 Exits
TruEra, the AI observability platform, is to be acquired by Snowflake, for an undisclosed sum.
Tempus AI, the intelligent diagnostics and data company for healthcare, filed to IPO. Their S-1 makes for a great read to understand the value of creating, collecting, and licensing real-world patient data for biopharma.
Signing off,
Nathan Benaich and Alex Chalmers 2 June 2024
Air Street Capital | Twitter | LinkedIn | State of AI Report | RAAIS | London.AI
Air Street Capital invests in AI-first entrepreneurs from the very beginning of your company-building journey.
