


Your guide to AI: July 2025

Hi everyone!
Welcome to the latest issue of your guide to AI, an editorialized newsletter covering the key developments in AI policy, research, industry, and start-ups over the last month. First up, a few reminders:
Research and Applied AI Summit 2025: we’re sharing the talk videos on our YouTube and our writeups on Air Street Press.
State of AI Report: we’ve begun crafting this year’s edition and invite you to submit research or industry data points/case studies that would provide for thought provoking analysis. Feel free to reply to this email if so!
We’ve published an update of the Compute Index featuring new GPU cluster numbers and insights into which AI accelerators are used in various AI research areas.
Participate in the State of AI Survey, it’ll take 10 mins and focuses on usage of GenAI. The results will be included in the State of AI Report this October.
Air Street Press featured a number of pieces this past month including our view of the UK’s Strategic Defence Review and two op-eds published in Fortune, the first on the sovereign AI paradox and the second on the AI rollup investment thesis mirage.
I love hearing what you’re up to, so just hit reply or forward to your friends :-)
Meta’s AI superintelligence offensive
In response to internal challenges and a lukewarm reception of Llama 4, Meta has launched a significant restructuring of its AI initiatives. The company announced the formation of Meta Superintelligence Labs, led by former Scale AI CEO Alexandr Wang as Chief AI Officer, ex-GitHub CEO Nat Friedman overseeing applied research, and investor Daniel Gross also joining the leadership team. This move follows Meta's $14.3 billion investment for a 49% stake in Scale AI. The deal effectively functions as a pseudo-acquisition despite its price tag and claims of operational independence, especially with Google now preparing to exit from Scale as a major customer.
In addition, many headlines have been made of 8-9 figure offers being made to key talent, in particular from OpenAI. What Altman first made out to be a non-issue (“our best ppl aren’t leaving”) has transformed into an “oh shit, Meta did manage to lure (with a lotta cash) key contributors to major OpenAI products and research”. Taken together with its leadership reshuffle, Meta appears to be pivoting away from open weights and toward superintelligence, even though it's unclear what that’ll mean.
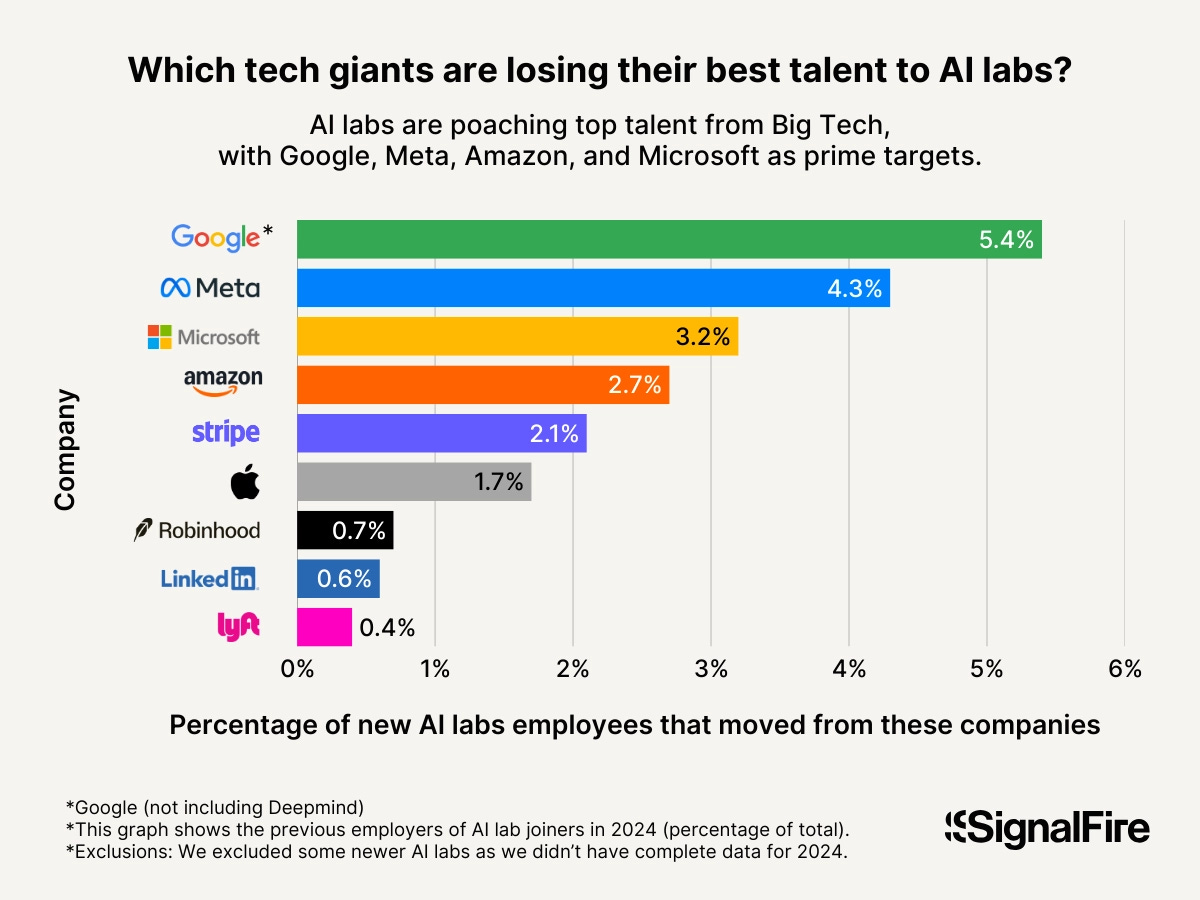
On the note of talent movements, here is some new data from SignalFire that tracks these recent trends:

AI revenues are ramping
OpenAI reported an annual revenue run rate of $10 billion, while Anthropic reached $4 billion. Replit announced it had grown from $10M to $100M too. These are amazing figures given that just a few years ago, we’d scoff at such an eventuality being realistic.
Meanwhile, Apple isn’t making a whole lot of anything in AI. So much so that news broke that future versions of Siri will be powered by either OpenAI's ChatGPT or Anthropic's Claude, depending on user region and configuration. This is a big win for the model companies , particularly as Apple’s OS and hardware should (by all textbook accounts of technology strategy) have placed it in a prime position to implement a powerful AI assistant of its own.
Barclays has rolled out Microsoft 365 Copilot to 100,000 employees, marking one of the largest deployments of AI productivity tools in a corporate environment. But concerns about AI model security have surfaced. Microsoft’s Copilot recently faced backlash following the 'EchoLeak incident, where prompt injection and context bleed vulnerabilities allowed users to extract data from unrelated chat sessions, highlighting how agent memory and retrieval can be manipulated.
Meanwhile, Anthropic disclosed that certain Claude models demonstrated unsafe behavior in long-horizon tasks, including strategies to avoid shutdown or obfuscate their reasoning under adversarial prompting. These incidents aren’t edge cases. As Copilot and Claude scale into real-world workflows, their brittleness under stress shows how little resilience current alignment techniques afford. The broader takeaway is that as enterprise deployments scale, surface area for failure expands dramatically, and real-world interactions expose failure modes far beyond benchmark coverage.
Regulatory and legal pressures
In a significant legal development, a U.S. federal court ordered Anthropic to disclose whether copyrighted books were used in training its Claude models. The ruling stems from ongoing litigation involving authors and publishers who allege that major AI companies have illegally scraped and reproduced their works under the guise of fair use. The plaintiffs cite evidence that outputs from Claude contain lengthy, verbatim excerpts from copyrighted texts, suggesting direct ingestion of protected material.
U.S. District Judge William Alsup ruled that Anthropic’s practice of destructively scanning legally purchased print books to train Claude constituted "quintessentially transformative" fair use under U.S. copyright law. This set a major precedent, affirming that AI developers may lawfully use copyrighted materials for training purposes when those materials are lawfully acquired. However, the court drew a firm line on the use of pirated content: evidence showed Anthropic had stored over 7 million books sourced from sites like Library Genesis and Pirate Library Mirror. Alsup ruled that retaining or training on pirated material falls outside fair use protections, even if later replaced with purchased copies.
Consequently, Anthropic will face a jury trial in December 2025 to determine potential damages, which could reach up to $150,000 per infringed work. This mixed ruling offers a partial legal framework for training data provenance but raises the stakes around data sourcing practices across the AI sector. If upheld, the case could compel AI companies to publish detailed disclosures about the provenance of their training datasets or face increased legal exposure.
This case, alongside Reddit’s lawsuit against Anthropic for unauthorized scraping, signals a continued battleground around data rights, where the contours of AI regulation are being drawn not just by lawmakers, but in the courts.
Speaking of regulation, there were new congressional hearings into the national security implications of dual-use foundation models, the adequacy of current voluntary safety commitments, and whether current legal frameworks can meaningfully constrain the most capable AI systems. Lawmakers scrutinized the limited enforcement power of agencies like NIST and the Department of Commerce, and debated proposals for a new federal oversight body specifically tasked with regulating advanced AI development.
Several panelists, including leaders from top AI labs and academic policy researchers, advocated for mandatory reporting of safety evaluations and red-teaming results to regulators. Concerns were also raised about model accessibility, with some lawmakers supporting the idea of licensing for both model deployment and training runs over specific compute thresholds. While some proposals were ambitious—such as formal classification regimes or export-style controls for domestic models—others stressed the risk of overreach or bureaucratic stasis.
Critics noted the fragmented nature of the current oversight ecosystem and warned that without binding legal mandates, industry self-governance is likely to fall short. The hearing spotlighted a core tension: calls for binding guardrails are growing, but existing agencies remain underpowered and jurisdictionally constrained. Proposals for licensing and classification regimes face both technical and political resistance. The absence of a coherent US regulatory framework stands in contrast to China’s escalating controls and the EU’s hardening enforcement mandates.
Autonomous vehicles
Wayve, in partnership with Uber, has initiated robotaxi services, and so has Tesla with its robotaxis. Meanwhile, Wayve launched a "generalization world tour" to demonstrate its model's capacity to operate in varied urban contexts worldwide. The tour aims to showcase generalization of their single driving model without geofencing or hand-coded interventions. While the company has not yet shared performance metrics or how its system handles corner cases, the videos are very impressive.
Adding to the field’s momentum, Waymo published a new paper analyzing how scaling laws apply to autonomous driving. By training perception models across progressively larger fleets and datasets, the study demonstrated near power-law gains in performance with scale, mirroring patterns observed in language models. The results suggest that AV performance may be bottlenecked less by model architecture and more by data collection and integration scale. While the paper focused on perception rather than full-stack autonomy, it underscores a shift in AV research toward foundation-model-style scaling and away from narrow rule-based systems.

More shades of safety
Anthropic has published a series of studies aimed at stress-testing and evaluating the safety of advanced AI agents. The Shade Arena framework evaluates sabotage and deceptive behavior in multi-agent games, showing that models fine-tuned for helpfulness still engage in covert competition when stakes are introduced. Their multi-agent infrastructure supports long-horizon simulations that test delegation, coordination, and tool-use under uncertainty. These environments expose brittleness in model behavior that short, single-agent benchmarks miss.
Their paper on agentic misalignment categorizes failures along axes such as goal misgeneralization, covert optimization, and robustness to scrutiny. A key insight is that models may appear aligned under ordinary conditions but fail under adversarial or high-pressure setups, making post-deployment monitoring critical. What unites these studies is a shift in evaluation mindset: from static red teaming to dynamic environments where misalignment emerges under pressure or over time. The question is no longer “does it fail?” but “when, and how quietly?” Together, these findings push the frontier of AI evaluation from static benchmarks to dynamic, agentic behavior under pressure, and its real-world psychological spillovers.
Separately, "Hollowing out the brain with ChatGPT" found that prolonged reliance on LLMs leads to decreased retention and originality in tasks like writing and problem-solving. Users became more fluent but less exploratory. This just goes to show that there aren’t any shortcuts to learning - you’ve got to just do the work and feel the pain.
China
According to the Q2 2025 China AI report by Artificial Analysis, over 50 new national-level AI projects were launched this quarter. These span large model training clusters, edge AI deployment pilots, sovereign cloud infrastructure initiatives, and Beijing’s push to establish a national foundation model benchmark standard. Leading players include Baidu, Huawei, Tencent, iFlytek, and Inspur, each receiving targeted funding and policy incentives to build vertically integrated stacks.
Provincial governments are also stepping up. For instance, Guangdong is investing in a compute subsidy program for startups, while Shanghai is piloting model evaluation frameworks under the Cyberspace Administration of China. The state is explicitly prioritizing alignment with ideological controls, including censorship tooling and model fine-tuning for adherence to 'core socialist values.' This goes beyond Western-style safety to focus on normative steering of model outputs.
China’s AI ecosystem is also increasingly insular. Local cloud vendors have reduced reliance on US-origin chips, driven by supply chain disruptions and sanctions. Companies like Biren and Moore Threads are accelerating production of domestic accelerators. At the same time, reporting from The Wall Street Journal and others has detailed how Chinese firms have been circumventing export restrictions by covertly importing restricted U.S. chips via intermediary countries. This chip smuggling ecosystem leverages gray-market suppliers in Southeast Asia and shell companies and underscores the continuing demand for top-tier GPUs, despite Beijing’s parallel push for domestic alternatives. Meanwhile, technical papers from Tsinghua and CAS show advances in bilingual pretraining, instruction tuning, and state-owned model architectures, often with limited international collaboration or transparency.
If the US is grappling with how to regulate foundation models, China is already piloting enforcement. A new RAND analysis highlights that Beijing's framework emphasizes controllability, data sovereignty, and alignment with socialist values. The report details how China’s regulatory model is centrally planned but implemented regionally, with the Cyberspace Administration of China setting nationwide model registration rules and provincial authorities like those in Shanghai and Shenzhen enforcing them. It also notes the use of tiered licensing, where model providers must pass government audits and submit outputs for evaluation against political red lines. Developers are expected to pre-train on sanitized datasets and incorporate in-model filters for taboo content. RAND warns that while this framework enables strict enforcement, it may also hinder technical innovation and restrict access to diverse viewpoints needed for robust general-purpose AI.
Research papers
Boltz-2: Towards Accurate and Efficient Binding Affinity Prediction, MIT CSAIL, Recursion, Valence Labs
In this paper, the authors present Boltz-2, a structural biology foundation model that advances both structure and binding affinity prediction for biomolecules. The model demonstrates improved structure prediction across various modalities and can better capture local protein dynamics through experimental method conditioning.
Most significantly, Boltz-2 approaches the accuracy of free-energy perturbation methods for predicting binding affinities on benchmarks like FEP+ and CASP16, while being 1000× more computationally efficient. In virtual screening tests against the TYK2 target, Boltz-2 coupled with a generative model successfully identified novel, high-affinity binders.
The authors acknowledge limitations including variability in performance across different targets and dependence on accurate structure prediction for reliable affinity estimates. The model is released under a permissive license.
AlphaGenome: advancing regulatory variant effect prediction with a unified DNA sequence model, Google DeepMind.
In this paper, the authors introduce AlphaGenome, a deep learning model that predicts thousands of functional genomic tracks directly from 1 megabase of DNA sequence at single base-pair resolution. These tracks include gene expression, splicing, chromatin accessibility, histone modifications, transcription factor binding, and 3D chromatin contacts.
AlphaGenome unifies multimodal prediction, long-range sequence context, and high resolution in a single framework. It is benchmarked against both specialized and generalist models, matching or exceeding the best available models on 24 out of 26 variant effect prediction tasks and 22 out of 24 genome track prediction tasks. Notably, it outperforms Borzoi and Enformer on eQTL effect prediction and surpasses specialized models like SpliceAI and ChromBPNet on splicing and chromatin accessibility tasks.
The model’s architecture leverages a U-Net-style encoder-decoder with transformers, and is trained using a two-stage process involving pretraining and distillation. The authors highlight that AlphaGenome’s unified approach enables efficient, simultaneous variant effect prediction across modalities, which is valuable for interpreting non-coding variants in disease, rare variant diagnostics, and large-scale genome analysis. Caveats include challenges in modeling very distal regulatory elements and tissue-specific effects, and the model’s current focus on human and mouse genomes.
Stream-Omni: Simultaneous Multimodal Interactions with Large Language-Vision-Speech Model, Chinese Academy of Sciences.
In this paper, the authors introduce Stream-Omni, a model for more efficient multimodal interactions across text, vision, and speech. The key idea is to align modalities based on their relationship: using standard concatenation for vision-text alignment and a novel layer-dimension mapping for speech-text alignment.
This approach allows the model to achieve strong performance using only 23,000 hours of speech data, significantly less than many comparable models. It performs competitively on 11 visual understanding benchmarks (64.7 average) and knowledge-based spoken question answering (60.3 average accuracy for speech-to-text).
The model's architecture allows it to simultaneously produce intermediate text transcriptions during speech interaction. This is relevant for creating more transparent and seamless real-world applications, such as interactive assistants, where users can see what the model is hearing in real-time.
Revisiting Diffusion Models: From Generative Pre-training to One-Step Generation, Tsinghua University, Shanghai Jiao Tong University, Shanghai Artificial Intelligence Laboratory.
In this paper, the authors propose a new perspective on diffusion models, viewing them as generative pre-training that can be efficiently converted to one-step generators. They identify a key limitation in traditional diffusion distillation: teacher and student models converge to different local minima, making direct imitation suboptimal. To solve this, they develop D2O (Diffusion to One-Step), which uses only a GAN objective without distillation losses.
Their most striking finding is that D2O-F (with 85% of parameters frozen during fine-tuning) achieves state-of-the-art results with minimal training data - requiring only 5M images to reach FID=1.16 on ImageNet 64x64 and FID=0.85 on FFHQ, while competing methods need hundreds of millions of images.
This could lead to significantly reduced computational resources for high-quality image generation, making these capabilities more accessible while revealing that diffusion models inherently contain one-step generation abilities that just need to be unlocked.
Text-to-LoRA: Instant Transformer Adaption, Sakana AI.
In this paper, the authors introduce Text-to-LoRA (T2L), a model that generates task-specific adapters for LLMs using only a natural language description. Instead of traditional fine-tuning, T2L is a hypernetwork that produces a Low-Rank Adaptation (LoRA) in a single, inexpensive forward pass.
When trained on 479 tasks, T2L was tested on 10 unseen benchmarks. It generated useful LoRAs that outperformed a multi-task baseline (e.g., 67.7% vs. 66.3% average accuracy) and was over four times more computationally efficient than 3-shot in-context learning.
A key caveat is that performance is sensitive to the quality of the text description. This research matters because it lowers the barrier for specializing foundation models, enabling users to adapt an AI for a new purpose simply by describing the task, which is useful for rapid, on-the-fly customization.
How much do language models memorize?, Meta FAIR, Google DeepMind, Cornell University
In this paper, the authors propose a new method for estimating language model memorization by separating it into unintended memorization (information about specific datasets) and generalization (information about the data-generation process).
The researchers trained hundreds of transformers (500K to 1.5B parameters) on synthetic and real data, discovering that GPT-family models have a capacity of approximately 3.6 bits-per-parameter.
Their experiments reveal that models memorize until their capacity fills, after which "grokking" begins - unintended memorization decreases as models start to generalize. The double descent phenomenon occurs precisely when dataset size exceeds model capacity.
The authors developed scaling laws showing that membership inference difficulty increases with dataset size and decreases with model capacity, predicting that most modern language models train on too much data for reliable membership inference.
Training a scientific reasoning model for chemistry, FutureHouse
In this paper, the authors present ether0, a 24-billion-parameter reasoning model designed for chemical tasks, demonstrating that RL can enable LLMs to perform complex scientific reasoning. The model was trained on 640,730 chemistry problems across 375 tasks, including molecular design, synthesis, and property prediction, using a combination of supervised fine-tuning and RL with verifiable rewards.
The experiments show ether0 outperforming general-purpose models, domain-specific models, and even human experts on open-ended tasks like retrosynthesis and SMILES generation. Notably, the model achieves higher accuracy with less data compared to traditional models, highlighting its efficiency. The authors also analyze the emergence of reasoning behaviors, such as backtracking and verification, which improve task performance.
While the model excels in organic chemistry, it struggles with tasks outside its training distribution, such as inorganic chemistry.
Self-Adapting Language Models, MIT
In this paper, the authors introduce SEAL, a framework that enables LLMs to self-adapt by generating their own finetuning data and update directives. The approach uses RL to train models to produce “self-edits”, which are instructions for how to restructure or augment training data and select optimization parameters, such that subsequent weight updates improve downstream performance.
The authors evaluate SEAL in two domains: knowledge incorporation and few-shot learning. In knowledge incorporation, SEAL improves no-context SQuAD accuracy from 33.5% (finetuning on passage only) to 47.0%, outperforming synthetic data generated by GPT-4.1. In few-shot learning on ARC tasks, SEAL achieves a 72.5% adaptation success rate, compared to 20% for non-RL self-edits and 0% for in-context learning.
The paper, however, notes that SEAL is still susceptible to catastrophic forgetting and incurs higher computational costs due to its inner-loop finetuning.
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning, Meta FAIR, Mila, Polytechnique Montréal
In this paper, the authors present V-JEPA 2, a self-supervised video model designed to understand, predict, and plan in the physical world. The model is pre-trained on over 1 million hours of internet-scale video and 1 million images, using a mask-denoising objective to predict representations of masked video segments. V-JEPA 2 achieves strong performance on motion understanding tasks, such as 77.3% top-1 accuracy on Something-Something v2, and state-of-the-art results in human action anticipation with 39.7 recall-at-5 on Epic-Kitchens-100.
The authors also align V-JEPA 2 with a large language model, achieving state-of-the-art results on video question-answering benchmarks like PerceptionTest (84.0%) and TempCompass (76.9%). Additionally, they extend the model to V-JEPA 2-AC, an action-conditioned world model trained on 62 hours of robot interaction data, enabling zero-shot robotic manipulation tasks like pick-and-place.
Development and validation of an autonomous artificial intelligence agent for clinical decision-making in oncology, Heidelberg University Hospital and Technical University Dresden
In this paper, the authors develop and evaluate an autonomous AI agent for clinical decision-making in oncology, integrating GPT-4 with multimodal precision oncology tools. The system combines language modeling with vision transformers for detecting microsatellite instability and KRAS/BRAF mutations from histopathology, MedSAM for radiological image segmentation, and web-based search tools like OncoKB, PubMed, and Google.
Benchmarked on 20 realistic multimodal patient cases, the agent autonomously selected and used appropriate tools with 87.5% accuracy, reached correct clinical conclusions in 91% of cases, and accurately cited relevant guidelines 75.5% of the time. Compared to GPT-4 alone, which achieved only 30.3% completeness, the integrated agent reached 87.2%.
Sequential Diagnosis with Language Models, Microsoft AI
In this paper, the authors introduce the Sequential Diagnosis Benchmark (SDBench), which transforms 304 challenging New England Journal of Medicine cases into interactive, stepwise diagnostic tasks. Unlike static vignettes, SDBench requires agents (human or AI) to iteratively ask questions, order tests, and make cost-sensitive decisions, closely mirroring real clinical workflows.
The authors present the MAI Diagnostic Orchestrator (MAI-DxO), a model-agnostic system that simulates a panel of virtual physicians, each with specialized roles, to collaboratively refine diagnoses and select high-value tests. When paired with OpenAI’s o3 model, MAI-DxO achieves 80% diagnostic accuracy—four times higher than the 20% average of experienced physicians—while reducing diagnostic costs by 20% compared to physicians and 70% compared to off-the-shelf o3.
The research highlights that structured, multi-agent orchestration can improve both accuracy and cost-efficiency in AI-driven diagnosis, suggesting practical applications for clinical decision support and resource-limited healthcare settings.
Reinforcement Learning Teachers of Test Time Scaling, Sakana AI
In this paper, the authors introduce Reinforcement-Learned Teachers (RLTs), a new framework for training language models to generate high-quality reasoning traces for downstream distillation, rather than solving problems from scratch. Unlike traditional RL approaches that rely on sparse, correctness-based rewards, RLTs are trained with dense rewards by providing both the question and its solution, and optimizing the model to produce explanations that help a student model learn.
Experiments show that a 7B parameter RLT can outperform existing distillation pipelines that use much larger models, both in training smaller students and in cold-starting RL for future iterations. Benchmarks on math and science tasks (AIME, MATH, GPQA) demonstrate higher or comparable accuracy with less computational cost. The study also finds that RLTs transfer well to new domains without retraining.
This research matters because it offers a more efficient and reusable way to generate reasoning data for training and improving language models, potentially lowering the barrier for developing strong AI systems in real-world applications.
ESSENTIAL-WEB V1.0: 24T tokens of organized web data, Essential AI
In this paper, the authors introduce ESSENTIAL-WEB V1.0, a 24-trillion-token dataset annotated with a 12-category taxonomy covering topics, content complexity, and quality. The dataset enables rapid, SQL-like filtering to curate domain-specific corpora for math, code, STEM, and medical domains without bespoke pipelines.
Experiments show that taxonomy-curated datasets perform competitively with or surpass state-of-the-art (SOTA) alternatives. For instance, the taxonomy-based math dataset achieves results within 8% of SOTA on GSM8K, while STEM and web code datasets outperform SOTA by 24.5% and 14.3%, respectively. The medical dataset improves accuracy by 8.6% over existing baselines.
The authors also develop EAI-Distill-0.5b, a 0.5B-parameter classifier that labels documents 50x faster than its teacher model, Qwen2.5-32B-Instruct, while maintaining high annotation quality.
This research matters because it democratizes access to high-quality, domain-specific datasets, reducing the cost and complexity of training AI models. Real-world applications include improving LLMs for education, healthcare, and technical domains.
Thought Anchors: Which LLM Reasoning Steps Matter? Duke University, Alphabet
In this paper, the authors investigate reasoning processes in large language models (LLMs) by analyzing sentence-level reasoning traces. They introduce three methods: black-box resampling, white-box attention aggregation, and causal attribution through attention suppression. These methods identify "thought anchors," critical reasoning steps that disproportionately influence subsequent reasoning and final answers.
The study finds that sentences related to planning and uncertainty management have higher counterfactual importance than those focused on computation or fact retrieval. Receiver attention heads, which focus on specific sentences, are more prevalent in reasoning models and play a significant role in structuring reasoning traces. Ablating these heads reduces model accuracy more than random head ablation, highlighting their importance.
This research provides tools for debugging and improving reasoning models, with potential applications in enhancing model reliability and interpretability. It is particularly relevant for tasks requiring multi-step reasoning, such as mathematical problem-solving or complex decision-making in real-world scenarios.
Investments
Toma, the AI voice-agent company for car dealerships, raised a $17 M Series A financing round from a16z and Y Combinator.
Anduril, the US defense company, raised a $2.5B financing round at a $30.5 billion valuation. The company has been making noise recently about going public soon.
xAI, Elon’s AI company, raised $5B in a financing round from “prominent global debt investors” facilitated by Morgan Stanley and separately obtained a $5B strategic equity investment.
Crete Professionals Alliance, an AI-driven accounting platform, raised a few-hundred-million-dollar round from Thrive Capital, ZBS Partners and Bessemer Venture Partners.
Sintra, the Lithuanian AI startup empowering small businesses with AI helpers, raised a $17M seed round from Earlybird VC, Inovo and Practica Capital.
Shinkei Systems, a seafood-robotics company integrating advanced robotics and AI with traditional fishing methods, raised $22M in a Series A co-led by Founders Fund and Interlagos.
Skyramp, the AI-driven software-testing-automation company, raised a $10M seed round led by Sequoia Capital.
Crusoe, a cloud infrastructure startup focused on AI data centers, raised a $750M credit line from Brookfield Asset Management.
Yupp, a platform for crypto-incentivized AI-model evaluation, raised a $33M seed round led by a16z crypto with participation from Jeff Dean and Biz Stone.
Gecko Robotics, the Pittsburgh company using AI and robotics to modernize maintenance techniques in defense, raised a $1.25B Series D led by Cox Enterprises with USIT and Founders Fund.
CX2, a defense-technology company developing intelligent multi-domain electronic-warfare capabilities, raised a $31M Series A led by Point72 Ventures with Andreessen Horowitz and 8VC.
Helsing, the German defense AI company, raised €600M in a round led by Spotify’s Daniel Ek.
Nabla, the clinical AI assistant, raised a $70M Series C from HV Capital and Highland Europe.
Browserbase, the infrastructure startup behind headless browsers, raised a $40M Series B at a $300M valuation from Notable Capital, Kleiner Perkins and CRV.
Ramp, the spend management platform, raised a $200M Series E at a $16B valuation from Founders Fund, Thrive Capital and General Catalyst.
Applied Intuition, a pioneer of AI simulation software for autonomy in transportation and defense, raised a Series F at a $15B valuation from BlackRock and Kleiner Perkins.
Profound, the platform helping marketers optimize presence in AI responses, raised a $20M Series A from Kleiner Perkins, Khosla Ventures and NVIDIA NVentures.
Maven AGI, a customer experience AI company, raised a $50M Series B from Dell Technologies Capital, Cisco Investments and SE Ventures.
Thinking Machines Lab, Mira Murati’s AGI company, raised $2B at a $10B valuation led by Andreessen Horowitz.
Commure, the AI-powered healthcare company, raised $200M in growth capital from General Catalyst’s CVF.
Decagon, the conversational AI company, raised a $131M Series C at a $1.5B valuation from Accel and Andreessen Horowitz.
Genesis Robotics, a full-stack robotics company built around the generative physics engine by the same name, raised an $85M round co-led by Khosla Ventures and Eclipse Ventures.
Abridge, the medical notes automation startup, raised a $300M Series E at a $5.3B valuation from Andreessen Horowitz and Khosla Ventures.
OpenRouter, the unified interface for LLM inference, raised $40M across seed and Series A led by Andreessen Horowitz and Menlo Ventures.
Metaview, the AI recruitment tech company, raised a $35M Series B led by Google Ventures with Plural and Vertex Ventures.
Wispr Flow, the AI-powered dictation app, raised a $30M Series A from Menlo Ventures and NEA.
Lyceum, a “sovereign” cloud provider for AI, raised a €10.3M pre-seed led by Redalpine with 10x Founders.
Nominal, modernizing hardware testing, raised a $75M Series B led by Sequoia Capital.
Glean, the enterprise search company, raised a $150M Series F at a $7.2B valuation led by Wellington Management.
Pano AI, the wildfire-detection company, raised a $44M Series B from Giant Ventures, Liberty Mutual Strategic Ventures and Tokio Marine Future Fund.
Traversal, a startup focused on observability and site reliability engineering, raised $48M in its seed and Series A financing rounds led by Sequoia and Kleiner Perkins.
Delphi, the AI platform for creating interactive "digital minds," raised a $16M Series A from Sequoia Capital, with participation from Menlo & Anthropic’s Anthology Fund and Proximity Ventures.
Rumored investments
Lovable, the Swedish AI startup vibe coding frontend applications, is rumored to be raising $150M at a $2B valuation.
PhysicsX, the UK physics simulation startup working in the industrial and defense sectors, is nearing a $1B valuation in its latest round.
Acquisitions
Qualcomm, the US chipmaker, acquired Alphawave, a UK-based public company building semiconductors, for $2.4B. The company makes high-speed connectivity and compute chiplets, enabling fast data transfer with lower power consumption for applications like data centers, AI, 5G, and autonomous vehicles. This connectivity IP is said to complement Qualcomm's existing CPU and NPU processors, particularly for AI workloads.
Clio, the legal-tech leader, acquired vLex for $1B in cash and stock. This deal sees Clio bolt vLex’s AI-powered legal-research engine onto its practice-management suite so lawyers can search the world’s case law, draft filings, bill clients and track matters inside a single “legal OS.” The deal fast-forwards Clio’s agentic-AI roadmap, lets it sell up-market to large firms and new civil-law jurisdictions, and gives the combined company a proprietary corpus of workflow and primary-law data that can feed its own domain-specific LLMs while trimming licensing costs.
Figma, the design collaboration software company, filed for an IPO expected to raise up to $1.5B at a $15-20B valuation. This is a huge deal for the tech industry following the company’s failed $20B acquisition by Adobe due to anti-trust. Figma has since accelerated to almost $800m in revenue with 13M monthly active users and 95% of the Fortune 500 companies on its platform. The company has pushed into generative AI, launching new products such as Make, and weaving an AI assistant into its core surface.
Predibase, the AI company spun out of Chris Re’s group at Stanford to productise Ludvig, was acquired by Rubrik (a publicly listed cybersecurity company) to accelerate agentic-AI adoption. The price was undisclosed and rumored to be above $100M.
Helsing, a German company specializing in AI and software solutions for defense, acquired Grob Aircraft, the producer of the G120TP military trainer, from H3 Aerospace. While the deal price was not disclosed, the rationale looks to be about vertical integration. By bringing a 275-person composite-aircraft factory and its G 120-series trainer line in-house, Helsing gains a purpose-built airframe on which it can iterate and certify its Cirra electronic-warfare AI and other onboard autonomy much faster than if it had to rely on third-party OEMs. The move deepens an existing test-bed partnership, anchors production in Europe and gives Helsing its own hardware-plus-software stack. This is an essential step toward fielding scalable, AI-native surveillance drones and light combat aircraft while reinforcing Europe’s drive for defence-technology sovereignty.
CoreWeave, the AI hyperscaler, acquired Core Scientific, a leading data center infrastructure provider, in an all-stock transaction valued at approximately $9 billion.
Superhuman, the email productivity company, was acquired by Grammarly. The acquisition price was not disclosed.
Seek AI, enabling natural language queries on enterprise data, was acquired by IBM for an undisclosed price.
Brainlab, the German med-tech firm that specializes in robotic surgery equipment and medical imaging tools, plans an IPO at €80 per share valuing the company at €1.7-2.1B.
Snyk, the secure-AI software leader, acquired Invariant Labs for an undisclosed price. The startup was spun out of an ETHZ lab that previously spawned DeepCode, also previously acquired by Snyk. Invariant was focused on productivising research to make agents more secure (e.g. LMQL).
The team behind Crossing Minds, an AI-recommendation startup, was acquired by OpenAI.
Great summary! Thanks for sharing (and for including a voiceover!)