


🏖️ Your guide to AI: July 2024


Prefer the audio version? Listen to it here
Hi everyone!
Welcome to the latest issue of your guide to AI, an editorialized newsletter covering the key developments in AI policy, research, industry, and startups over the last month. But first, a few intro points from us:
Thank you to everyone who attended this year’s Research and Applied AI Summit (RAAIS) last month. It was great to see both old and new friends and peek into the future of AI breakthroughs. We've started to share videos of the talks here. More to come!
If you’re in Vienna for ICML later this month, I’m bringing together a small group of AI tech and research friends for dinner. Register interest here.
Don’t forget to subscribe to Air Street Press to receive all our news, analysis and events directly in your inbox. Recent pieces have included an analysis of the economics of general intelligence, and advice from Thought Machine founder Paul Taylor on finding your start-up idea. Coming up next week will be our take on the AI copyright wars.
We’re releasing more and more of our content in audio form for those of you who listen on the go, or multi-thread modalities :-), including this newsletter and all prior ones - check it out on Spotify here.
We love hearing what you’re up to and what’s on your mind, just hit reply or forward to your friends :-)
🌎 The (geo)politics of AI
Safety Island has changed governments. In a result that shocked precisely no one, the British public evicted AI enthusiast and Summit organizer-in-chief Rishi Sunak, returning the center-left Labour Party to government after a 14-year hiatus. The Labour Party have kept their cards pretty close to their chest, so it’s hard to say exactly what they’re planning for the tech sector, but their manifesto gives us a few clues. Ultimately, the previous government managed to keep tech non-political and there are few disagreements of substance between the main parties.
It is likely that the UK will pass limited legislation to regulate the most powerful foundation models, but stop short of an EU-style general AI regulation. At the same time, it’s no secret that new prime minister Keir Starmer lacks his predecessor’s interest in AI. The AI Summit and the AI Safety Institute came into being as a result of Sunak’s personal patronage. It remains to be seen if the new government will give such initiatives the resources and focus they need to have an impact.
Regardless of future summits, fans of multilateralism will be dismayed by the continued escalation in US-China tech tensions. In late June, the US Treasury Department confirmed that the government would move beyond merely restricting the export of technology and instead begin barring outbound investment in Chinese companies working on certain strategic technologies.
Along with quantum and semiconductors, the rule looks set to restrict investment into Chinese AI companies working on a broad range of applications deemed detrimental to national security, including defense, surveillance, and audio, image, or video recognition. They are also exploring introducing a compute threshold and specific restrictions around companies that primarily use biological sequence data.
At this stage, measures like this serve more as a warning shot to both investors and the tech sector. While certain US VCs probably do have questions to answer about their past China investments, major firms have stayed clear of the country’s AI sector for the past couple of years or spun off their China businesses. Rules like this remind the tech sector more widely - whether it’s investors, foundation model providers, or hardware manufacturers - that the restrictions are going to keep coming. It’s likely not a coincidence that the timing of this notice coincided with OpenAI’s warning that it would begin blocking Chinese users from accessing ChatGPT.
Another dispute that only appears to be deepening is the AI copyright war. While OpenAI continues to strike deals with media publishers to avoid ugliness, the music industry has opted for violence. The Recording Industry Association of America (RIAA) announced that it was suing music generation services Suno and Udio for massive infringement of copyright. Pointing to close similarities between artists’ work and generated music, the RIAA argues that large volumes of copyrighted music were used as training data by the companies. While neither company is forthcoming on the makeup of its training data, neither has explicitly denied using copyrighted material. Expect much heated argument over fair use definitions.
While the music lawsuit was always a fight waiting to happen, another front has opened up, with media organizations rounding on buzzy AI search engine Perplexity. The starting gun was fired by Forbes, which claimed the company’s new Perplexity Pages content curation feature was plagiarizing a raft of media outlets. They pointed to how passages had been lifted word-for-word, along with custom illustrations, from their reporting on a drone project, with limited citation. Said ‘plagiarized’ post was also turned into a podcast and a YouTube video. Perplexity said that the product was in its early days and that they would improve attribution. Forbes has threatened to sue the company.
Wired rowed in behind Forbes, pointing to similar incidents with its own content. More concerningly, it presented evidence that the company was deliberately circumventing attempts by websites to block its crawler via their robots.txt file by using a pool of secret IP addresses. Perplexity blamed an unnamed third party provider, refused to confirm that it would stop doing this, and noted that robots.txt is “not a legal framework”. While technically true, this does strike us as a violation of the internet’s social contract. To the authors’ likely amusement, Wired was then able to point to Perplexity apparently plagiarizing its reporting on its own alleged plagiarism…
While not every copyright claim is equally valid, it’s clear that this is going to be a running sore for the industry. Our view, which we outline in a forthcoming essay on Air Street Press, is that some kind of compromise on this issue is likely inevitable. It’s likely in the industry’s best interest to work this out as amicably as possible, rather than to have one imposed by either the courts or via the political process.
🍪 Hardware
The legal rows continue as we move into hardware. In a new report, France’s competition authority has expressed concern about the market power of certain actors in the generative AI space. Like similar reports from other competition authorities, they point to overlapping investments and alleged conflicts of interest. First in their crosshairs is NVIDIA, which looks set to face antitrust charges. While we don’t know the details yet, the competition authority’s report specifically warned of a potential conflict of interest around NVIDIA’s investment in CoreWeave and expressed concern about CUDA’s GPU lock-in (sidebar: we’ve written about this in the Press recently). This is unlikely to quell complaints about European authorities’ prioritization of regulation over innovation - building the most popular GPUs probably shouldn’t be a criminal offense...
Another geography keen to see an end to NVIDIA dependence is China, but all is not well in the country’s domestic semiconductor efforts. The 2023 State of AI Report documented China’s claimed breakthrough in sanctions-busting chips, but Noah Smith has documented how Huawei’s A100 copycat appears to have failed, with 80% of those produced so far malfunctioning.
A full 80% of the Ascend 910B chips designed for AI training are defective and SMIC is struggling to manufacture more than small batches. Huawei executives have all but admitted defeat. This, of course, does nothing about the large stockpiles of NVIDIA hardware big Chinese labs have stockpiled or continue to smuggle into the country. The former can’t be solved, the latter probably can be. However, the argument from sanctions skeptics that the measures would provide a significant boost to the domestic chip making industry don’t appear to have aged well. Instead, it looks like Chinese companies are continuing to rely on sanctions-compatible chips, despite the game Whac-A-Mole manufacturers are playing with the Commerce Department. NVIDIA looks set to make $12B on the delivery of 1M of its new H20 chips to the Chinese market.
As well as being a good time for NVIDIA, things are also looking up for AI infrastructure providers. As well as a multi-billion dollar deal with xAI, Oracle is now helping OpenAI meet its compute needs. While Microsoft will continue to provide compute for pre-training, Oracle’s cloud infrastructure will now support inference.
All of this work comes at a cost. Google’s 2024 Environmental Report contained the stark admission that the company will struggle to meet its net zero goals. In fact, the company’s greenhouse gas emissions had jumped 48% since 2019, primarily as a result of its AI work. We’re likely to see the clash between net zero commitments made in haste a few years ago and the physical requirements of the AI boom emerge as a theme in the coming months.
In this newsletter, we often talk about compute, cloud infrastructure, and training - but what does this actually mean in practice? If you’ve ever wanted to know what setting up a cluster is actually like, the Imbue team have recently published a fascinating step-by-step guide. Check it out here.
🏭 Big tech start-ups
Last month’s Guide to AI contained much about OpenAI’s woes, but the company received a ray of good news after Elon Musk dropped his lawsuit against the company. Musk had brought the action earlier this year, alleging that the company had breached its original not-for-profit mission - an argument that didn’t appear to hold much water once OpenAI disclosed historic emails between Musk and the founding team.
Things got better still with the news that Apple is to integrate ChatGPT into both Siri and its system wide Writing Tools. Apple will also gain a board observer role, elevating them to the same status as Microsoft, and leading to some potentially interesting meetings. Apple is still in talks with Anthropic and other companies about potential integrations, but reportedly turned Meta down on privacy grounds. Given the two’s long-standing feud on the subject, the news doesn’t come as a surprise.
While Apple’s in-house AI team has released a raft of papers over the last few months (more on that later) detailing their progress on efficient LLMs that could run on-device, the company has so far struggled to productize this work. Its grab-bag of writing and emoji generation tools are yet to set the world on fire. A salutary reminder that even when you’re one of the world’s most valuable companies, the journey from good science to good product is still extremely challenging.
One AI product that won’t be seeing the light of day anytime soon is OpenAI’s voice assistant (of Scarlet Johansson kerfuffle fame), with the company saying that more time is needed for safety testing. This kind of responsible release strategy will be music to the ears of departed co-founder and AI safety devotee Ilya Sustkever, who has re-entered the arena along with former Apple AI lead Daniel Gross and former OpenAI engineer Daniel Levy, to launch Safe Superintelligence (SSI). Ilya and the two Daniels are promising the “world’s first straight-shot SSI lab” that will be “insulated from short-term commercial pressures”.
The founding team’s star power means initial fundraising is unlikely to be a challenge, but the new venture’s backers will essentially be gambling that i) we really are approaching superintelligence in the near future that is monetizable, ii) a team can catch up with frontier labs capitalized to the tune of billions of dollars from a standing start, iii) the emphasis on safety won’t be an impediment to fast progress. They’ll be taking all of these risks while accepting there will be no attempt by the company to generate revenue anytime soon. Brave. Then again, some readers will be old enough to remember the era when DeepMind would always be free to work on long-term research without having to worry about revenue…
Returning to the land of products and commercial pressures, Anthropic released Claude Sonnet 3.5, its most capable model yet. The model manages to outperform Opus across every benchmark, while costing less.
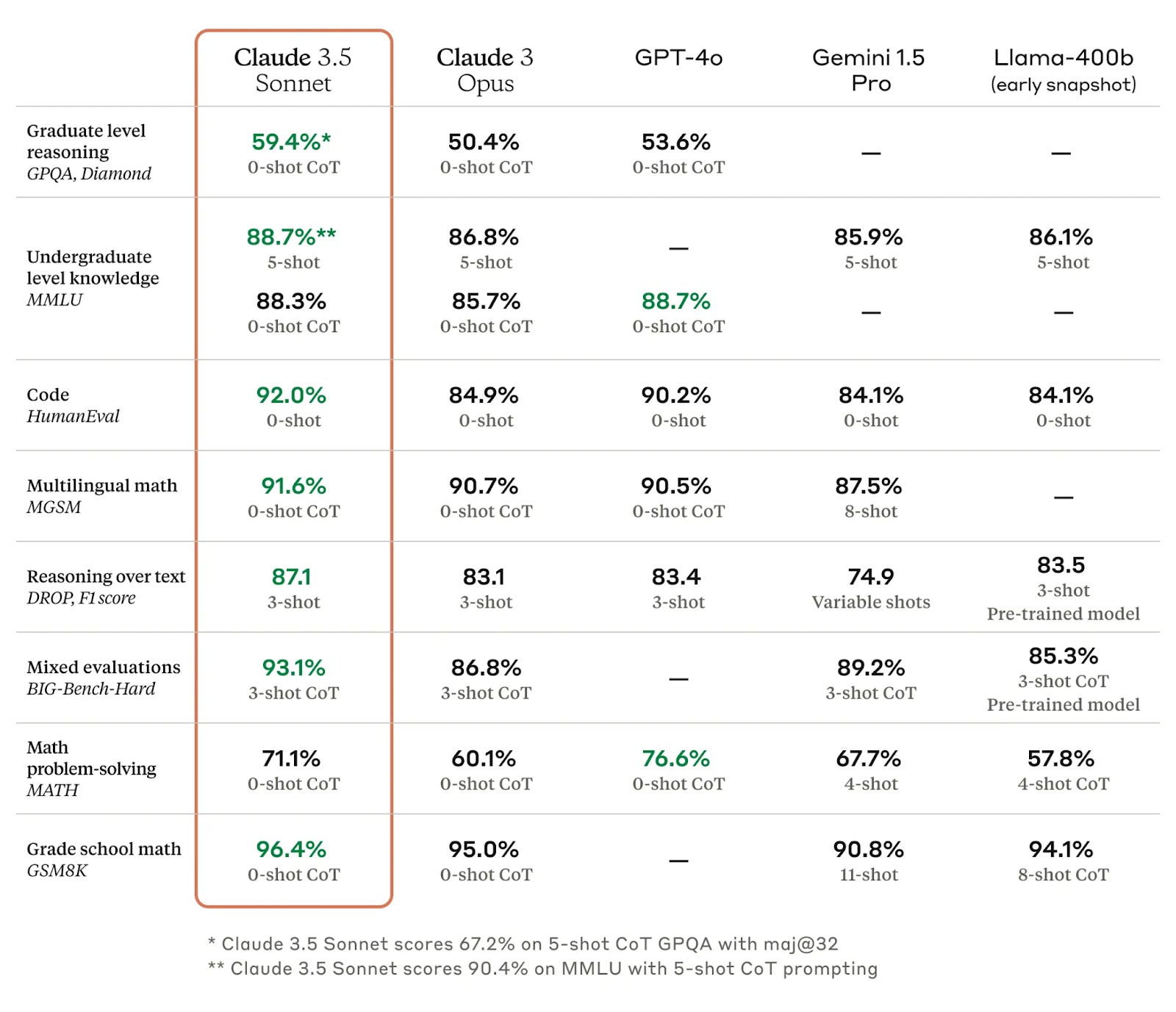
These results reinforce the sense that the gap between GPT-4 and the rest has essentially closed - with the top of the LMSYS leaderboard a three-way tie between Sonnet, GPT-4o, and Gemini Advanced. For AI safety fans, the model was submitted to the UK’s AI Safety Institute for pre-release testing - to our knowledge, the first time a major lab has done this. No further details on this testing were shared.
Anthropic paired the Sonnet announcements with the reveal of Artifacts, which puts code snippets, text documents, or website designs generated by Claude in a separate window, allowing users to edit them in real-time. There’s a demo video here. The people loved this.
Elsewhere, Runway released one of the most impressive accessible (OpenAI’s Sora remains heavily gated) text-to-video models yet. Trained jointly on videos and images, Gen-3 Alpha will underpin Runway's Text to Video, Image to Video and Text to Image tools. The company is keen to stress the controllability the user has over the output (a common criticism of text-to-video), along with the steps forward in fidelity and consistency. Generations remain confined to 10 seconds, but this may be addressed in larger models in the Gen-3 family that will be released further down the line. It is worth noting that these performance gains aren’t cheap - text to video is a resource intensive business and each 10-second clip will cost between $1 and $2.40. No wonder you can’t use it without paying.
🔬Research
Meta 3D Gen, Meta.
This paper introduces 3DGen, a pipeline for generating 3D assets from text descriptions. The process is quick, producing high-quality output within a minute and supports physically-based rendering for realistic lighting effects. As well as creating new assets, it can retexture assisting ones using text inputs, unlocking applications in fields like gaming, AR/VR, and content creation.
The 3DGen pipeline is structured in two stages. The first stage, Meta 3D AssetGen, transforms text prompts into initial 3D meshes with corresponding textures and PBR material maps. This stage leverages a multi-view and multi-channel approach to generate consistent views of the object, which are then reconstructed into a 3D shape. The second stage, Meta 3D TextureGen, refines the textures generated in the first stage or applies new textures to existing 3D meshes.

3DGen integrates these stages to create a system that effectively represents 3D objects in view space, volumetric space, and UV space. This integration improves the fidelity and visual quality of the generated assets, outperforming peers in speed and in the accuracy of prompt adherence. The system's efficiency and quality make it particularly suitable for professional use, where time and precision are critical.
Simulating 500 million years of evolution with a language model, EvolutionaryScale.
This paper introduces ESM3, the debut model from the EvolutionaryScale team, who previously worked on protein design at Meta and built ESM2. The model is trained on a massive dataset of billions of natural and synthetic protein sequences and structures. The team augmented the training set with annotations and predicted structures.
ESM3 generates protein sequences using a transformer-based model that integrates sequence, structure, and function information. It masks random parts of protein sequences during training, teaching the model to predict these missing parts. This is meant to provide a better representation of evolutionary processes than next-token prediction. A discrete autoencoder compresses 3D protein structures into simpler tokens, while an attention mechanism captures how different parts of the structure interact.

The model was tested by prompting with specific structural and functional constraints, demonstrating an ability to produce high-quality structurally valid proteins. The researchers tested it at different scales to test the effect of model size on performance, with the largest model hitting 98B parameters. They found that deeper networks, rather than wider ones, were the most effective at learning protein representations.
The model is available with a non-commercial license - the same access terms as AlphaFold 3. The appendix of this paper is a gold mine for tricks and tips.
A Multimodal Generative AI Copilot for Human Pathology, Harvard Medical School.
This paper presents PathChat, a multimodal AI assistant tailored for human pathology. PathChat combines a vision encoder pretrained on histopathology images with an LLM, and is fine-tuned on over 450,000 pathology-specific instructions. The researchers evaluated PathChat against other AI models on multiple-choice diagnostic questions and open-ended pathology queries.
On multiple-choice questions, PathChat outperformed other models in diagnostic accuracy, especially when provided with both histology images and clinical context. For open-ended questions, seven pathologists ranked model responses, with PathChat producing the strongest answers.

The researchers also explored potential use cases for PathChat, demonstrating its ability to describe morphological features, suggest diagnostic workups, and engage in multi-turn conversations for differential diagnosis. They note PathChat's potential applications in pathology education, research, and clinical decision support.
Manipulate-Anything: Automating Real-World Robots using Vision-Language Models, University of Washington, NVIDIA, Allen Institute for Artificial Intelligence, Universidad Católica San Pablo.
This paper introduces MANIPULATE-ANYTHING, a framework designed for zero-shot robotic manipulation task generation and execution using vision-language models (VLMs). It leverages the capabilities of VLMs like GPT-4V for task decomposition, action generation, and verification, as well as Qwen-VL for object information extraction. The framework aims to provide a scalable and environment-agnostic solution that can autonomously generate demonstrations for various robotic tasks without requiring prior environment information.
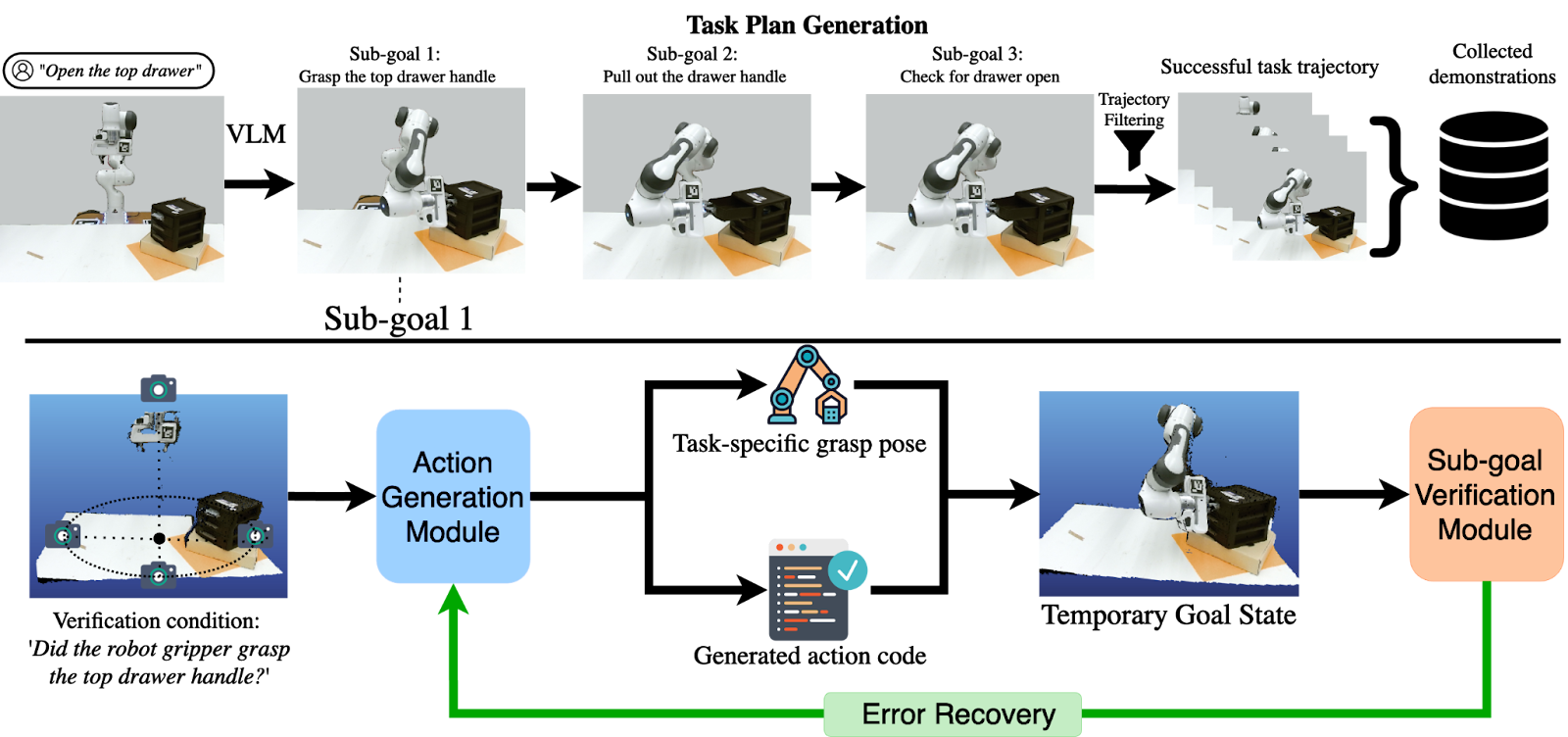
The study evaluates MANIPULATE-ANYTHING in simulation and real-world scenarios. In simulations, it outperforms existing methods, such as VoxPoser and Code as Policies (CAP), in 9 out of 12 tasks. The tasks range from simple actions like "put_block" to the more complex, like "play_jenga" and "open_jar". The success rate is measured based on the system's ability to complete tasks with diverse object instances and configurations, highlighting its generalization capabilities.
Real-world experiments involve using a Franka Panda robot with a Kinect 2 RGB-D camera to perform five tasks: open_jar, sort_objects, correct_dices, open_drawer, and turn_on_lamp. MANIPULATE-ANYTHING demonstrates a high similarity in action distribution compared to human-generated data and achieves comparable success rates.
Also on our radar:
4M-21: An Any-to-Any Vision Model for Tens of Tasks and Modalities, Apple. This paper introduces 4M-21, an improved version of the 4M pre-training framework, which aims to handle diverse tasks and modalities by transforming different types of data (like images and text) into a common format of discrete tokens. This model increases the number of supported modalities from 7 to 21, incorporating inputs such as images, text, 3D human poses, and more. Using specialized tokenizers, the model converts various inputs into token sequences and employs a masked training objective to predict parts of these sequences from others.
An Image is Worth 32 Tokens for Reconstruction and Generation, Bytedance. This paper introduces TiTok, a novel approach to image tokenization that uses a 1-dimensional latent representation instead of the traditional 2D grid. By leveraging vision transformers and vector quantization, TiTok can compress images into as little as 32 tokens while maintaining high reconstruction quality. The authors demonstrate that this compact representation enables faster and more efficient image generation compared to existing methods, while achieving competitive or superior results on ImageNet benchmarks
LLM Dataset Inference: did you train on my dataset?, Carnegie Mellon University, University of Toronto, CISPA Helmholtz Center for Information Security. This paper tackles the challenge of identifying whether specific text sequences or datasets were used to train LLMs. The authors argue that the standard approach of using membership inference attacks - which test differences in how a model behaves when presented with data it was trained on versus data it hasn't seen before - is unreliable in practice. They propose a novel dataset inference attack, which combines multiple membership inference attack techniques to create feature vectors for text samples, then uses a linear model to learn which features best distinguish between suspect and validation datasets.
Open-Endedness is Essential for Artificial Superhuman Intelligence, Google DeepMind. This position paper makes the case that open-ended models - those able to produce novel and learnable artifacts - will be essential to reach some form of AGI. The authors argue that current foundation models, trained on static datasets, are not open-ended. They outline potential research directions for developing open-ended foundation models, including reinforcement learning, self-improvement, tasing generation, and evolutionary algorithms.
CRAG - Comprehensive RAG Benchmark, Meta. CRAG consists of 4,409 diverse question-answer pairs across multiple domains, question types, and temporal dynamics, along with mock APIs for web and knowledge graph searches. The benchmark reveals significant challenges in current RAG solutions, with even state-of-the-art systems achieving only 63% accuracy without hallucination. CRAG's design allows for analysis of RAG performance across various dimensions, highlighting areas for improvement such as handling dynamic information and complex reasoning tasks.
Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks, Microsoft. This paper introduces Florence-2, a vision language model, designed to handle a variety of vision tasks through a unified, prompt-based architecture. The model is trained on the FLD-5B dataset, which contains 5.4B annotations across 126M images, generated autonomously to encompass diverse spatial hierarchies and semantic granularities. The pre-training on FLD-5B enhances training efficiency by four times and results in substantial performance improvements across multiple benchmarks, such as COCO and ADE20K, despite the model’s relatively compact size. Microsoft released a 200M and 800M parameter model, with the 200M outperforming Flamingo 80B, a 400x larger peer. When finetuned with publicly available human-annotated data, the model was competitive with SOTA models like PaLiI and PaLI-X.
RouteLLM: An Open-Source Framework for Cost-Effective LLM Routing, LMSYS Org. This work introduces RouteLLM, a framework that aims to optimize the use of large language models by directing queries to either more capable but expensive models or less capable but cheaper models, depending on the query's complexity. Using preference data from Chatbot Arena and various augmentation techniques, the researchers trained four different routers that significantly reduced costs while maintaining high performance across benchmarks like MT Bench, MMLU, and GSM8K. The best-performing routers achieved up to 85% cost reduction compared to using only GPT-4, while still reaching 95% of GPT-4's performance.
Can Language Models Serve as Text-Based World Simulators?, University of Arizona, Microsoft Research, NYU, John Hopkins, Allen Institute for AI. This paper introduces a new benchmark called BYTESIZED32-State-Prediction, containing datasets of text game state transitions, to quantitatively assess LLMs' simulation capabilities. They find GPT-4 struggles with environment-driven transitions and complex reasoning tasks involving arithmetic, common sense, or scientific knowledge. They conclude current LLMs will not reliably serve as standalone world simulators without further innovation.
Are We Done with MMLU?, University of Edinburgh. The authors argue that the popular MMLU benchmark contains a high number of mistakes, including the wrong ground truth, unclear questions, or multiple correct answers. These were particularly stark in certain fields, such as virology, where 57% of the analyzed instances contained errors. When run on MMLU-Redux, a manually annotated correct MMLU subset created by the researchers, most models gained in performance, although on certain topics such as professional law and formal logic, models performed worse. This suggests inaccurate MMLU instances are being learned in models’ pre-training.
💰Startups
🚀 Funding highlight reel
AlphaSense, the market research platform, raised a $650M round led by Viking Global Investors and BDT & MSD Partners.
Alinia AI, working on AI alignment for enterprise, raised a €2.2M pre-seed, led by Speedinvest and Precursor Ventures.
Bright Machines, the start-up eliminating manual labor from electronics manufacturing, raised a $106M Series C, led by BlackRock.
Cruise, the self-driving car company, received an $850M investment from General Motors.
Cube, building a universal semantic layer, raised a $25M round, led by 645 Ventures.
Eko Health, creating a modernized stethoscope, raised a $41M Series D, with participation from Artis Ventures, Highland Capital Partners, NTTVC and Questa Capita.
Enveda Biosciences, a biotech company engineering new drugs from plants, raised a $55M Series B2, from investors including Premji Invest, Microsoft, the Lingotto Investment Fund and the Nature Conservancy.
Etched, building an ASIC designed for transformer models, raised a $120M Series A, led by Primary Venture Partners and Positive Sum.
Greptile, using AI to help developers understand code bases, raised a $4M seed, led by Initialized Capital.
Mistral AI, the French foundation model challenger, raised a €600M Series B, led by General Catalyst.
Norm AI, converting regulations and corporate policies into computer code, raised a $27M Series A, led by Coatue.
Orby, building AI agents for enterprise workflows, raised a $30M Series A, led by New Enterprise Associates, Wing Venture Capital, and WndrCo.
Pika, developing an AI-powered platform for film editing and generation, raised an $80M Series B, led by Spark Capital.
Sentient, an open platform for AGI development, raised an $85M seed, led by Founders Fund.
Sixfold AI, using generative AI to improve the insurance underwriting process, raised a $15M Series A, led Salesforce Ventures.
Speak, the AI-powered language learning app, raised a $20M Series B extension, led by Buckley Ventures.
Stability AI, building models for image, audio, and video generation, raised an $80M funding round from investors including Coatue, Lightspeed Venture Partners, and Eric Schmidt.
Twelve Labs, building models to understand videos, raised a $50M Series A, co-led by New Enterprise Associates and NVentures.
Waabi, developing autonomous driving technology, raised a $200M Series B, led by Khosla Ventures and Uber.
Wordsmith, the query-answering workspace for in-house lawyers, raised a $5M seed, led by Index Ventures.
🤝 Exits
Hyperplane, building foundation models for banks, was acquired by Nubank.
OpenAI made two acquisitions: Multi, the collaborative software-building platform and Rockset, to improve its retrieval infrastructure. Terms were not disclosed for either deal.
Tegus, the expert research provider, was acquired by AlphaSense in a $930m deal.
Uizard, which uses generative AI to generate product designs, was acquired by Miro.
Signing off,
Nathan Benaich and Alex Chalmers 7 July 2024
Air Street Capital | Twitter | LinkedIn | State of AI Report | RAAIS | Events
Air Street Capital invests in AI-first entrepreneurs from the very beginning of your company-building journey.

Recently, OpenAI acquired the data warehouse company Rockset. The rationale behind this move isn't necessarily about the intrinsic value of data warehouses for RAG (Retrieval-Augmented Generation). Rather, compared to other data warehouses, Rockset is more of an indexing database. It creates inverted indexes for every column in a table, thereby offering keyword full-text search capabilities similar to Elasticsearch. Combined with vector search, this database inherently supports these two types of hybrid search capabilities. At this stage, there are very few options that offer this combination. Additionally, Rockset adopts a cloud-native architecture, and these two factors combined are the main reasons for OpenAI's decision.