
🔥 Your guide to AI: February 2023


Hi all!
Welcome to the latest issue of your guide to AI, an editorialized newsletter covering key developments in AI research, industry, geopolitics and startups during January 2023. This one is a monster so it might get clipped in your inbox (read the online version in case!). Before we kick off, a couple of news items from us :-)
Nathan wrote an oped in The Times for why university spinouts are a critical engine for our technology industry and why spinout policy needs urgent reform. The Times Higher Education profiled our open source data term database, spinout.fyi.
Nathan commented on The Financial Times’ Big Read on The growing tensions around spinouts at British universities.
The State of AI Report provided two key figures to The Economist’s piece on The race of the AI labs heats up.
Register for next year’s RAAIS, a full-day event in London that explores research frontiers and real-world applications of AI-first technology at the world’s best companies.
As usual, we love hearing what you’re up to and what’s on your mind, just hit reply or forward to your friends :-)
🏥 Life (and) science
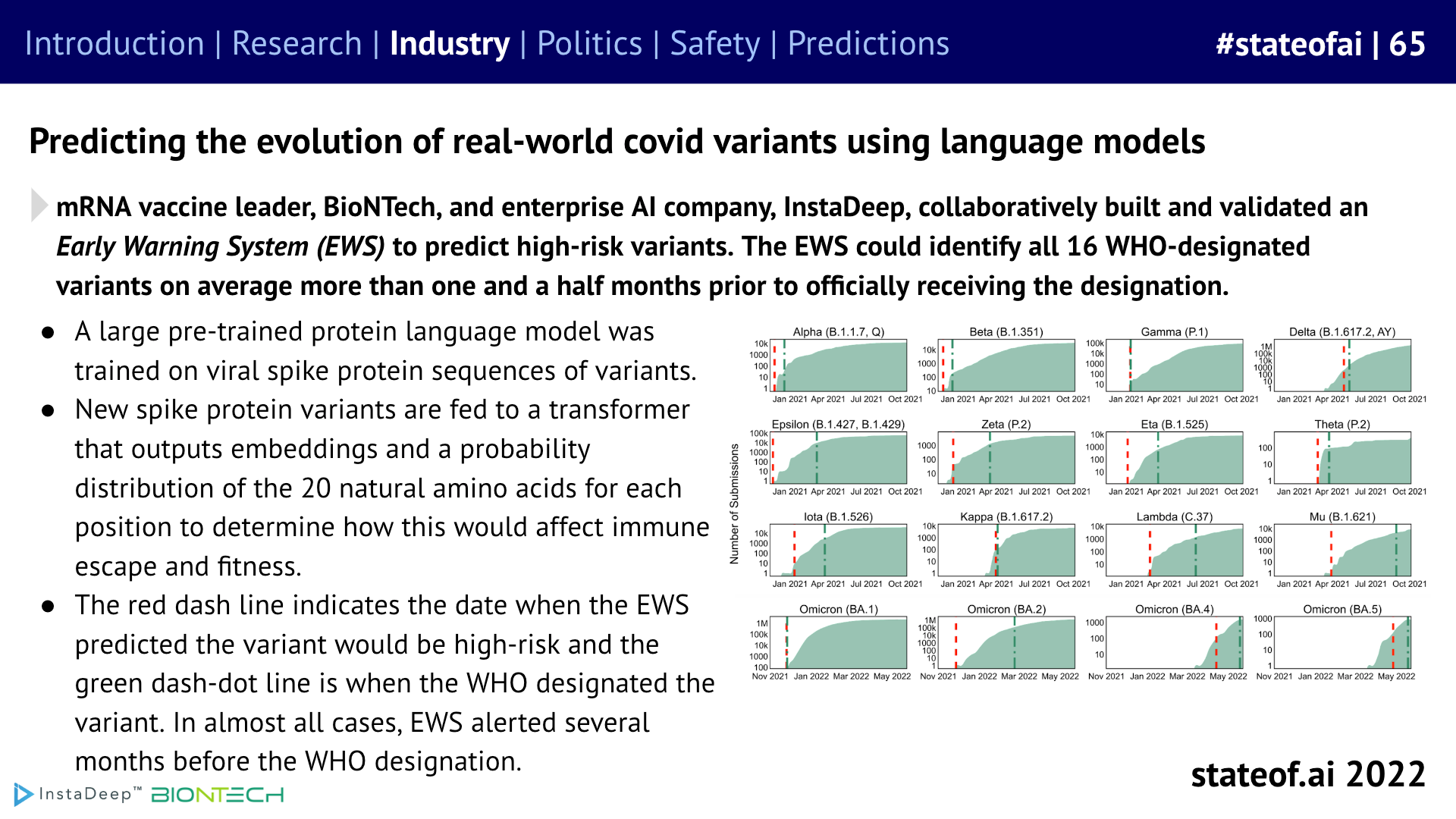
BioNTech acquired London and Tunis-based AI startup InstaDeep for $680M (cash + stock) - this was a huge deal. InstaDeep was born in 2015 with a mission to bring state of the art decision making AI systems into the enterprise. Largely bootstrapped until it raised a $7M Series A in 2019 and a $100M Series B in 2021, the company worked with teams on the earlier side of AI deployment (such as Deutsche Bahn, the largest rail operator in Europe) to companies with leading AI teams (such as Google and NVIDIA).
In the last few years, InstaDeep has also made strides in machine learning-based protein design by adding DeepChain, a protein design platform, to its portfolio of products. Astute readers of this newsletter will recall that in our Jan 2021 issue, we wrote about a Science paper demonstrating how language models could learn the language of viral evolution and escape. A year later, BioNTech and InstaDeep collaborated to produce a successful early warning system to detect potential high-risk Covid variants by making use of related approaches (see slide 65 from State of AI Report 2022 below). This deal sees BioNTech deepen its commitment to weaving increasingly capable AI systems throughout its workflows: “Our aim is to make BioNTech a technology company where AI is seamlessly integrated into all aspects of our work.”, Prof. Ugur Sahin, CEO of BioNTech.
At Air Street Capital, we continue to be bullish on the sector-wide overhauling of biotech to be AI-first by design. This month, we announced our investment into Profluent, a new AI-first protein design company founded and led by Ali Madani. Ali had previously led Salesforces’ moonshot project ProGen, during which his team showed in pioneering work how language models can be adapted to be a controllable tool to design proteins with predictable functions. With co-authors from the Profluent team Richard Socher (ex-chief scientist at Salesforce) and James Fraser (Bioengineering professor at UCSF) and other collaborators, they published their findings in an article published by Nature Biotechnology: Large language models generate functional protein sequences across diverse families.
Our portfolio company, Exscientia, announced the start of its fourth clinical trial. This time it is for a first-in-human immunology and inflammation candidate, EXS4318, which inhibits the PKC theta kinase that we know to play a critical role in controlling T cell function. Note that T cells help our immune system fight off specific foreign pathogens and support B cells in their production of antibodies. The drug molecule was designed by Exscientia and in-licensed by its partner, Bristol Myers Squibb, in summer of 2021. Proving out the efficiency of AI-first drug design, it took 11 months to find EXS4318, which was only the 150th novel compound the company synthesized during the campaign. For context, the industry averages 54 months and 2,500 molecules required to discover a drug candidate.
Meanwhile, Insilico Medicine announced positive topline results from their Phase 1 trial of INS018_055, a potential first-in-class small molecule for idiopathic pulmonary fibrosis (lung scarring). The trial recruited 78 healthy volunteers in New Zealand over the last year and showed a generally positive safety profile. The company is now awaiting approval to start a Phase 2 trial.
Just like every domain in AI, biology needs large and diverse datasets to help scientists make sense of its intrinsic complexity. Recursion has long been a pioneer in generating and publishing large open datasets, in their case microscopy data for cells treated with drugs, gene knockouts and other manipulations. The company conducts up to 2.2M experiments per week in a highly automated lab that generates arguably more than Twitter on a daily basis. With RxRx3, Recursion profiled over 17k genes and 1.6k known chemical entities and released 2.2M images of cells with associated embeddings. Datasets like these help biologists and machine learners generate maps of biology and chemistry that aid the discovery of novel therapeutic agents.
🌎 The (geo)politics of AI
Back in November 2022, Matthew Batterwick, “a writer, designer, programmer, and lawyer”, and litigators at Joseph Saveri Law Firm filed a lawsuit against Github Copilot – the OpenAI Codex-based coding assistant – for “open-source software piracy”. It was only a matter of time before text-to-image model developers started getting sued as well. In January, two suits were filed targeting Stability AI, the company behind the Stable Diffusion model. The first lawsuit came from the same parties of the Github Copilot lawsuit. It accuses DeviantArt and Midjourney as well of violating copyright law. Specifically, these companies are sued for their use of Stable Diffusion, a model described as “a 21st-century collage tool that remixes the copyrighted works of millions of artists whose work was used as training data.” The second one came from the supplier of stock images Getty Images, which is pursuing Stability AI on similar grounds. Getty Images, which is known for being aggressive on copyright infringement, chose a different path from Shutterstock, a competitor. The latter stroke deals with the likes of OpenAI and Meta – who were more cautious than Stability AI – to allow them to use millions of their images as training data in exchange for financial reward. Some argue Getty Images is playing hard ball to get a similar deal on better terms. You can read a brief coverage of these questions in this VentureBeat article. This begs a crucial question: what if you could certifiably detect if a given image, or text, was used to train a model? And on a tangentially related subject, what if you could confidently detect if something you see or read has been AI-generated? These two questions have one common answer: watermarks. Read on till the research section, where we highlight efforts by the research community to achieve these goals (some works long predate the latest debates!).
Perhaps a more pressing issue for society at large is the use of generative language models for propaganda and misinformation. This is an issue that has been discussed when access to AI models was restricted to a handful of actors, and mostly in the context of recommender systems and political ads on social media. But with the widening access to AI models as part of consumer products and the rapid progress in language model capabilities, understanding the threats of misinformation and propaganda through AI becomes a pressing matter for non-experts as well. A great paper from CSET, OpenAI, and Stanford University, Generative Language Models and Automated Influence Operations: Emerging Threats and Potential Mitigations, gives an excellent framework to think about this problem. Crucially, to safeguard society from misinformation, it’s not simply a matter of government regulation or corporate abstinence, it will increasingly be a matter of education. To that effect, giving the executive summary a read should be useful to having constructive debates around generative AI and misinformation.

As we covered in our previous edition, military AI companies benefit from increasingly larger VC checks, and some of them – Anduril for example – are capable of moving fast and releasing products either through internal innovation or through acquisitions. Congressional appropriators seem to think that some these products are good enough and developed fast enough that it is shutting down a 14-year running, $200M program for unmanned underwater vehicles, and advising the Navy to “integrate commercially available UUV technology into Navy and Marine Corps concept of operations development and resourcing, procurement and fielding plans.”
Last edition, we also covered Japan and the Netherlands' intent to join the US in restricting chip exports to China. The three countries made this official in late January by signing a trilateral agreement on the matter. Some US chip manufacturing companies were worried that the restrictions would give a competitive advantage to foreign companies like the Dutch ASML and the Japanese Tokyo Electron. Details of the agreement are kept secret – for now – but the Dutch prime minister indicated that the discussions included many more countries. Restrictions on exports of high-end chips could be only the beginning of a broader set of policies on technology transfer to Chinese AI companies. One vehicle of technology transfer is US investment in Chinese AI companies, which comes with mentorship, coaching, and networking opportunities. The main conclusion of a recent report from CSET that relied on data from Crunchbase was that loose disclosure requirements made it hard to track data on US investment in Chinese AI companies. While these investments may be limited, understanding the extent to which US financial investments help Chinese AI companies should be a priority in order to develop meaningful policies.
Finally, it seems we’re inching closer to a long fantasized US federal AI cloud lowering the barrier of access to compute. A White-House task force called the National Artificial Intelligence Research Resource (NAIRR) outlined a $2.6B budget over 6 years in order to build multiple agencies providing advanced computing capabilities to users. And it's not just large-scale compute clusters that are needed, but high-quality annotated data. The Pentagon’s AI Chief Digital and AI Officer made some waves by saying“If we’re going to beat China, and we have to beat China in AI, we have to find a way to label at scale. Because if we don’t label at scale, we’re not going to win.”
🏭 Big tech
Microsoft and OpenAI confirmed that they were extending their partnership (after their $1B investment in 2019) through a “multi-year, multi-billion dollar investment from Microsoft” to the tune of $10B according to sources. More details on the deal were reported by Semafor: Microsoft will supposedly get 75% of the profits, with a total capped at their initial investment of $10B. Days before the official deal was announced, Microsoft had made their Azure OpenAI Service available. This includes access through API to pretrained large language models, as well as Codex (a large transformer trained on language and fine-tuned on code), and DALL-E 2, OpenAI’s text-to-image model. People’s favorite ChatGPT will also soon be accessible on the service, of course. Meanwhile Microsoft has launched Teams Premium, with a range of features (intelligent recap, AI-generated chapters, notes, tasks, translations, etc.) powered by OpenAI’s GPT 3.5. And since OpenAI profit is also Microsoft profit, both companies will be carefully checking the usage number on OpenAI’s new offering, ChatGPT Plus, which guarantees access to ChatGPT during peak times, offers faster response times, and early access to new features… for $20/user/month. On a side note, it is amusing how on a “Timeline of key Microsoft AI breakthroughs” (which is good to have in mind – see Image), Microsoft chose to start the timeline in September 2016 and highlight how most of its breakthroughs are actually OpenAI’s. Granted, the computing power is Microsoft’s, and this is a post about OpenAI, but hey, start 6 months earlier, tap yourselves on the back, and write in Microsoft’s ResNet, which is only the most popular deep learning model – its paper is the most cited in machine learning! – and maybe the most broadly deployed in AI-based products. Would Google forget Transformers as one of their breakthroughs?

Training all OpenAI’s models requires vast amounts of data. We’re used to neglectfully refer to LLMs as “trained on the internet” as a shortcut to saying that they’re trained without supervision on broadly available unlabeled and unstructured textual data. But the reality is that beyond careful choice of training data, humans are paradoxically an increasing present component of the training loop, through their feedback on model outputs and through instruction finetuning. These are needed on the one hand to improve the performance of the model, for example for coding and reasoning tasks, and on the other hand to limit harmful, violent and incorrect output. As it relates to the second issue, OpenAI recently came under fire in a TIME article for hiring Kenyan workers paid between $1.32 and $2 per hour through a San-Francisco-based form called Sama. It should be noted that this isn’t an isolated case, as Facebook had already signed a contract with the same firm whose work culture was said to be “characterized by mental trauma, intimidation, and alleged suppression of the right to unionize” according to another TIME story. As an important sidenote, it is important to remember that this approach of instruction finetuning and reinforcement learning from human feedback - which is lauded as the main reason for ChatGPT’s amazing performance - is an output of safety and alignment research.
Finally, to end a busy OpenAI news month, DeepMind’s CEO Demis Hassibis said in an interview that the company would release a ChatGPT competitor, called Sparrow, some time in 2023. DeepMind, an Alphabet company, will be more cautious and release their chatbot in private beta first. Meanwhile, Larry Page and Sergey Brin, Google’s co-founders, apparently participated in meetings to redefine Google’s AI product strategy as a response to the success of ChatGPT. As we were wrapping up this newsletter, perhaps the biggest news of the month came out: Google invested $300M worth of compute credits (or $400M depending on the sources) into Anthropic, OpenAI’s safety and alignment-focused competitor, which was founded by OpenAI alumni. An immediate thought is that Google, like Microsoft with OpenAI, is looking to duck the reputational risk from releasing unpredictable LLMs as part of consumer products by working with a startup that has much less to lose. There are many parallels to draw between Anthropic and OpenAI, including that Anthropic also released a Chatbot, called Claude, which was trained with Constitutional AI, a form of Reinforcement Learning with AI (vs. human for OpenAI) Feedback, that was recently published by Anthropic researchers. Anthropic will of course benefit from a partnership with Google Cloud that will allow it to train their models on TPUs just as OpenAI does with Azure, albeit on NVIDIA hardware.
Google laid off 6.4% of its staff, but the layoffs have apparently spared Google Brain, the company’s AI research lab. Much of the work of the division is now being refocused on delivering AI-based products (sidenote: this is super exciting). This doesn’t mean that Google is only cutting jobs in the (relatively) low-tech parts of their business, as layoffs didn’t spare Google subsidiaries Intrinsic (industrial robotics), Verily (life-sciences), and X (the moonshot factory, from which Intrinsic came out), but rather that layoffs in these businesses spared AI researchers, and concentrated in recruiting, business, and operations. The unicorn Scale AI, which works to make data labeling more efficient for training AI models, laid off 20% of its staff (700 people).
Apple, who’s the only Big Tech company which is seemingly immune to layoffs (for a variety of reasons…), silently released Apple Books digital narration. The announcement came without any clear technical explanation of what their text-to-speech technology was, but it’s certainly more impressive than existing mainstream offerings like Google Play Books’s auto-narrated audiobooks. But Google made its own substantial contribution to machine learning for audio, when its researchers released MusicLM, a model that generates music from a textual prompt – like DALL-E/StableDiffusion do for images. MusicLM is an extension of AudioLM, a model that “casts audio generation as a hierarchical language modeling task that first predicts semantic tokens, which are then used as a conditioning to predict acoustic tokens that can be mapped back to audio using a SoundStream decoder”. Music generation is nothing new – the latest well-known attempts at mastering it are OpenAI’s Jukebox, or more recently Riffusion; but the samples Google released seem to be a significant step towards robust, coherent music generation. Listen for yourself here.
🍪 Hardware
Dylan Patel, of semianalysis.com, wrote a case for the end of NVIDIA’s monopoly in machine learning that we feel was too ambitious vs. reality. Pytorch is arguably the most popular python deep learning framework used in large language models training. However, one challenge for non-NVIDIA hardware makers is that they need to develop over 2,000 optimized pytorch operators to their own hardware. By virtue of being the default backend, these operators were optimized for each of NVIDIA’s architectures. Patel argues that as abstractions (from Pytorch, OpenAI Triton, and others) which could transition seamlessly from a backend to another develop, NVIDIA’s software moat will no longer be one, and the difference between hardware makers will solely depend on the architecture and economics of the chip. OpenAI Triton is one way to realize this transition, since it makes hardware (e.g. GPU) programming easier (plenty of details in the article). But the fact that Triton only supports NVIDIA GPUs for now makes the case against CUDA (NVIDIA’s software) quite speculative. Check Soumith Chintala’s (one of Pytorch’s creators) mitigating arguments in this thread.
If CUDA isn’t inescapable yet, paying for hardware utilization is. One article from semianalysis and another from epochai examine the dollar cost of training large-scale AI systems. The first article details compute costs of state of the art language models and estimates, according to scaling laws derived by DeepMind, how much it would cost to make these models larger – which has been observed to generally be correlated with better performance on most language modeling tasks. For example, if DeepMind’s 70B-parameter model Chinchilla had been trained on A100 GPUs (it was trained on Google TPUs), it would have cost around $1.75M. Training a $10T-parameter dense model on 216,200 tokens (where would they find these?) would cost $29B! Epochai’s article’s goal is to predict the growth of training cost systems by 2030 based on historical trends. The author estimates that the cost of an average milestone ML system (think GPT-3, PaLM for example, but at scales which are implicitly predicted) will cost $500M ($90M to $3B with a 90% confidence interval).
🔬Research
Mastering Diverse Domains through World Model, DeepMind, University of Toronto. Coming up with a reinforcement learning algorithm that is applicable across diverse applications without hyperparameter tuning has been a challenge for the RL community. The researchers devised DreamerV3, an algorithm consisting of 3 neural networks (world model, critic, actor), which they applied successfully to 150 different tasks with a fixed set of hyperparameters. As is now expected (up to a certain point), they showed that increasing model sizes resulted in monotonic improvements in performance. Notably, DreamerV3 is the first algorithm to collect diamonds in Minecraft from scratch without human demonstrations. Remember that in Learning to Play Minecraft with Video PreTraining (VPT), OpenAI had hired contractors to play 2,000 hours of Minecraft in order to use recorded video labeled with mouse and keyboard actions as supervisory signal to their model.
On to our promised overview of recent works on watermarking and AI-generated content detection, whose legal ramifications we covered in the politics section.
Extracting Training Data from Diffusion Models, Google, DeepMind, ETH, Princeton, UC Berkeley. This work will probably be one piece of evidence used by prosecutors against Stability AI and others. It shows that Stable Diffusion (a model used by Stability AI) memorizes individual images and emits them at generation time. The authors are able to extract 1,000+ images, including ones with trademarked company logos. They further show that diffusion models are much more prone to generating images from their training set (they are less private) than other generative models like GANs (remember?).
Radioactive data: tracing through training, Facebook AI Research (this work dates back to 2020), INRIA. The authors propose a technique to imperceptibly modify images on a dataset such that the distribution of the output of models trained on any image from the dataset will have a lower loss on modified images than on the original ones.
A Watermark for Large Language Models, University of Maryland. The task here is to identify if generated text comes from a given language model. Since modifying a few letters in a word icn’t feasitle (huh?) without humans noticing, the researchers select a randomized set of “green” tokens that can seamlessly be inserted in generated text and that can be detected using an open-source algorithm without access to the language model API or parameters.
DetectGPT: Zero-Shot Machine-Generated Text Detection using Probability Curvature, Stanford University. The hypothesis that the authors work with is that model’s samples come from regions of negative curvature of the log probability function. Given initial access to the LM, the authors define a statistical criterion that, when appropriately thresholded, distinguishes between humans-generated text and LLM-generated text. Access to the model is a hindrance, but we could easily imagine OpenAI implementing and tuning DetectGPT for each of its models, and offering it as a service to schools, universities, web browsers, etc. Oh wait! They already did implement something (here).
The Nucleotide Transformer: Building and Evaluating Robust Foundation Models for Human Genomics, InstaDeep, NVIDIA, TUM. We briefly discussed how InstaDeep is making strides in AI applied to biology. This paper is one example of high-quality research they’re producing. In this work the researchers deal with the problem of predicting molecular phenotypes from DNA sequences alone. They pre-trained a range of transformer models of varying sizes on a dataset with sequences from the Human reference genome. They also collected sequences from 3,200 genetically diverse human genomes, as well as a custom multispecies dataset from 850 species. They showed that increasing model size and dataset diversity increased the average performances on downstream tasks. In particular, their largest model (2.5B parameters) beats existing methods on 15 of the 18 downstream tasks they compiled from existing literature.
Parsel : A (De-)compositional Framework for Algorithmic Reasoning with Language Models, Stanford University. One major difficulty that code LLMs (LLMs trained or fine-tuned on large code repositories) face is implementing code that requires multi-step reasoning. LLMs typically are not able to decompose the natural language specification of a coding problem into easier parts that are easier to generate. This work proposes to explicitly decouple the two phases: decomposing the problem into smaller subproblems, then generating code for each subproblem. They achieve this by developing a framework called Parsel, wherein hierarchical function descriptions are given, with each sub function having specific constraints (unit tests generally) that it needs to verify/pass. The descriptions for the decomposed problems would typically be given either by humans or by good natural language models trained to generate them. Once all the constraints of the subproblems are verified, they can be composed to solve the original problem. The authors test Parsel on competition-level problems of the challenging APPS dataset, and achieve 75% higher accuracy than existing results (this amounts to around 25% pass rates on those problems). They also apply their framework to robotic planning and formal theorem-proving.
💰Startups
Funding highlight reel
Anthropic raised $300M or $400M from Google, notably for reuse on Google compute platform. The funding could value the company at roughly $5B according to the New York Times. Anthropic is a direct competitor to OpenAI, but with a heavier focus on AI alignment and safety. This adds to the $700M the company had already raised, in large part from Sam Bankman-Fried. We wrote a few words about this in the Big Tech section.
Profluent raised a $9M seed round from Insight Partners, Air Street Capital, AIX Ventures and Phoenix Venture Partners. The company also released a paper in Nature Biotechnology showing that language models can generate functional artificial proteins with desired properties.
Metagenomi, a biotechnology firm that uses AI to discover unknown CRISPR gene editing systems, raised a $275M Series B led by Novo Holdings A/S, Catalio Capital Management and SymBiosis.
Character.ai, an LLM-powered chatbot company with a stellar engineering team, is rumored to be raising a $250M Series A.
Asimov, which develops a synthetic biology platform powered by ML and advanced computational tools, is raising a $200M Series B led by Canada Pension Plan Investment Board.
British AV developer Oxbotica raised a $140m Series C from Aioi Nissay Dowa Insurance, ENEOS Innovation Partners, and others.
Cologne-based DeepL, the best-known alternative to Google Translate, raised around a $100M round at 1B+ valuation
Creative Fabrica, “a marketplace for digital files like print-on-demand posters, fonts and graphics”, raised a $61M round led by Alven. The company recently integrated a tool that allows its users, many of which are artists, to generate images from text prompts, apparently using StabeDiffusion and OpenAI APIs.
Inbenta, a company providing conversational AI as a service and search for enterprises, raised a $40M round led by Tritium Partners.
Atomic AI, which uses AI for RNA drug discovery, and was founded by an intern of DeepMind’s AlphaFold team, raised a $35M Series A led by Playground Global.
Inscribe, an AI-powered document fraud detection service provider, raised a $25M Series B led by Threshold Ventures, while anti-money laundering and fraud detection platform Hawk AI raised a $17M Series B led by Sands Capital.
Lavender, which helps companies with email marketing through diverse AI tools including a writing assistant, raised a $13.2M Series A led by Norwest Venture Partners.
Supernormal, the N-th (N >> 1) company that develops a tool to automatically transcribe and summarize meetings, raised a $10M round led by Balderton.
Coho AI, which promises to help SaaS businesses grow faster thanks to better data utilization, raised a $8.5M seed round led by Eight Roads and TechAviv.
BloomX, which makes the bet that machine-learning models will make artificial pollination more efficient and more likely to succeed, raised a $8M seed round led by Ahern Agribusiness.
Seek, which is looking to put boring but hard to automate data insight requests away from data teams and closer to their end user through a natural language interface, raised a $7.5M seed round from Conviction Partners, Battery Ventures and former Snowflake CEO Bob Muglia.
Scenario, which allows game developers to use image generators trained on their games, raised a $6M seed round from multiple investors.
Lithuanian medical imaging company Oxipit raised a $4.9M round led by Taiwania Capital, Practica Capital and Coinvest Capital. The company was the first autonomous AI medical imaging application which was awarded the CE Mark, back in March 2022.
Exits
As discussed at the top of this issue, BioNTech acquired InstaDeep in a deal worth up to $680M. BioNTech was an investor in InstaDeep’s $100M Series B and is deepening its commitment to becoming an AI-first pharma company, weaving AI into as many of its workflows as it can.
Snowflake, the cloud data infrastructure company, acquired Myst AI to integrate time series forecasting capabilities for its customers. Myst was a small team 13 ppl focused on energy and utilities, helping these companies forecast demand. The company raised $8M in total. Congrats, Pieter, Titiaan and team!
HP Enterprise acquired Pachyderm, an opinionated data engineering and pipelining company that grew to focus on AI and MLOps. The business had raised $28M in total and was roughly 50 FTE.
---
Signing off,
Nathan Benaich, Othmane Sebbouh, 5 February 2023
Air Street Capital | Twitter | LinkedIn | State of AI Report | RAAIS | London.AI
Air Street Capital is a venture capital firm investing in AI-first technology and life science companies. We’re an experienced team of investors and founders based in Europe and the US with a shared passion for working with entrepreneurs from the very beginning of their company-building journey.

👏👏👏
Thank you!