


Your guide to AI: December 2024


Hi everyone!
Welcome to the latest issue of your guide to AI, an editorialized newsletter covering the key developments in AI policy, research, industry, and start-ups over the last month. First up, a few updates:
Amid the latest round of scaling laws hitting a wall of speculation, Nathan interviewed Eiso Kant, the co-founder and CTO of Poolside. In this 45 minute video, we discuss scaling laws, synthetic data, training infrastructure, reasoning, economics, and much more.
Nathan joined Matt Turck’s MAD Podcast to discuss the State of AI Report key findings. You can watch the chat on YouTube or listen on Apple.
We relaunched the RAAIS Fellowships - a cash grant and compute credit package for individuals/teams working on open source AI projects - we want to hear from you. For more details on what we’re looking for and how to apply, see here.
Congratulations to our friends at Odyssey, who raised a Series A round, led by EQT Ventures, with backing from Air Street and GV. You can read more about the team here and why we originally backed them in July here.
The Air Street Press continues to whir, with recent pieces covering drones, AI’s energy demands, Percy Liang on truly open AI, and the start of our State of AI outtakes series.
It was great to see so many friendly faces at London AI and Paris AI meetups in the last fortnight. We’ve reached the end of our events program for 2024, but we’ll be back on both sides of the Atlantic in 2025. Subscribe to our events page to ensure you don’t miss out.
Along with events, you can get all of our news, analysis, and events directly in your inbox if you subscribe to Air Street Press.
We love hearing what you’re up to and what’s on your mind, just hit reply or forward to your friends :-)
🌎 The (geo)politics of AI
Are we so back, or is it so over? Following this November’s US presidential election, it depends who you ask.
On the one hand, you have a Republican platform committed to repealing the Biden White House’s frontier AI executive order. On the other hand, Trump confidant Elon Musk supported California’s sweeping proposed AI regulation. Trump is a China trade wars enthusiast, Musk is a China dove. The prospective Secretary of the Department of Health and Human Services is a vaccine skeptic with a range of … eccentric views, but it’s unclear how much direct impact he’ll have on the biotech industry (beyond triggering a -10% downdraft in the XBI biotech index). Trump has no desire to spend more on defense or engage in overseas conflicts, but is rumored to be considering Anduril co-founder Trae Stephens for a senior role in the Department of Defense.
In short, the tech world is in ‘choose your own adventure’ mode. Whether you’re optimistic or pessimistic about the result, it’s possible to cherrypick appointees, past quotes, or implied policy positions and build your own Marvel Cinematic Universe about what the next four years will look like.
In reality, we just don’t know what a Trump Presidency will mean for AI. Considering the unpredictable personalities and the (short) median tenure of a Trump ally, it’s hard to predict the next six weeks, let alone the next six months.
If you want to read more about what we don’t know, but what will be some interesting debates to follow - Air Street Press has got you covered.
Are we living in the Leopold Aschenbrenner’s future? In this year’s State of AI Report, we poured cold water on the Situational Awareness author’s accelerationist fan fiction, which involved the nationalization of major AI labs to pave the way for an AGI Manhattan Project to save the free world.
But since then, the US-China Economic and Security Review Commission, an independent body that reports to Congress, released its 2024 Annual Report. Top of its list was recommending that “Congress establish and fund a Manhattan Project-like program dedicated to racing to and acquiring an Artificial General Intelligence capability”. The doomers on X responded in their characteristic manner: predicting the end of the world and sharing Shoggoth memes that we struggle to follow.
Before we get too excited, it’s worth remembering a few things.
Firstly, the USCC has no policymaking authority. While influential over some in the legislative branch, it probably represents the most hawkish wing of mainstream opinion on China.
Secondly, its specific recommendations - making funding available to US companies and procurement changes - seem rather tame compared to the original Manhattan Project.
Finally, as journalist Garrison Lovely has observed, the report is full of embarrassing technical inaccuracies, including describing OpenAI as a ‘model’, references to the non-existent “ChatGPT-3” product, and a bafflingly bad definition of AGI. That might give readers pause for thought.
But Team Safety can draw comfort from one source. Maybe government-run frontier evals are working?
Our friend, Logan Graham, who leads the Frontier Red Team at Anthropic, recently described the UK and US AI Safety Institutes as a rare example of “extreme competence/capacity” in government and a “99th %ile” outcome. He believes that they played a meaningful role in improving Sonnet’s robustness.
For people who don’t know what the AI Safety Institutes do, the joint UK/US blog post and technical report on Sonnet 3.5 testing give us a few clues. The teams tested the model’s capabilities against reference models and human baselines across a range of capabilities, spanning bio, cyber and software development, while probing the efficacy of their safeguards. They used a blend of public and privately-developed evaluations.
OpenAI can only dream of this kind of smooth pre-deployment experience. This week, its text-to-video generation model was apparently leaked on Hugging Face by disgruntled artists involved in testing it. They published an accompanying letter declaring that they were being used for “artwashing” and that: “Hundreds of artists provide unpaid labor through bug testing, feedback and experimental work for the program for a $150B valued company. While hundreds contribute for free, a select few will be chosen through a competition to have their Sora-created films screened — offering minimal compensation which pales in comparison to the substantial PR and marketing value OpenAI receives.”
Access was pulled within a couple of hours and OpenAI has refused to confirm whether the model in question was authentically Sora.
This is an interesting new front in the AI/art wars. It’s notable that the letter didn’t mention copyright anywhere and encouraged artists to use open source tools as an alternative. If frontier AI labs simply … pay their testers properly, a two-front war can likely be averted.
🍪 Hardware
NVIDIA enjoyed another blowout quarter, with quarterly revenue of $35.1B, up 17% on Q2 and 94% year-on-year. The vast majority of this came from the company’s data center business. As ever, despite exceeding consensus expectations, NVIDIA’s failure to meet the most extreme predictions actually caused the share price to fall slightly. This puts NVIDIA’s diluted earnings per share at 0.78, versus 0.47 for AMD and a truly horrifying -3.88 for Intel.
But Intel received one consolation prize in November. The company secured a $7.86B funding agreement via the CHIPS Act to support semiconductor manufacturing in Arizona, New Mexico, Ohio, and Oregon. A few billion in tax breaks have also been thrown in as a sweetener. This could be a last hurrah for the CHIPS Act, with Trump implying his preferred method of onshoring the supply chain would be tariffs. This was $600M smaller than the anticipated award and comes amid rumors that Qualcomm has lost interest in acquiring the company. While a blow to M&A lawyers everywhere, it means Qualcomm will be spared the task of running a loss-making semiconductor manufacturing business.
How is Intel loss-making amid a global semis boom? This is a question we might be returning to in an upcoming series on Air Street Press.
Are US sanctions on China achieving much? As we see stunning open models from Chinese labs (more on those below), the smart money would be on ‘no’. But while it’s easy to smuggle GPUs, smuggling advanced ASML lithography machines, which are both rare and roughly the size of a double-decker bus, is proving harder.
This explains why Chinese chip makers, like Huawei and SMIC are increasingly trying to push the limits of older ASML equipment. But if Bloomberg is to be believed, this approach isn’t working. This is because so-called ‘multi-patterning’, where a lithographic machine is forced to perform up to four exposures on a silicon wafer, is prone to alignment errors and yield losses - especially when done in conjunction with poor local equipment.
With western GPUs seemingly on tap, this may not currently matter for the best Chinese labs. But it does throw sand in the gears of the Chinese Communist Party’s long-standing policy of breaking dependence on western equipment. They’re apparently less optimistic about the long-term prospects of the GPU smuggling industry than many western commentators.
🏭 Big tech start-ups
Masa has landed, with OpenAI allowing Softbank to grow its stake in exchange for buying $1.5B in equity from employees, as part of a tender offer. Employees will have until 24 December to decide if they want to take part. There’s clearly logic to the deal for both sides. OpenAI naturally ties into the Softbank CEO’s 300 year-vision of the world, while a dollop of liquidity is likely not a bad way of motivating a workforce that’s seen a number of departures recently.
Anthropic have continued on their recent tear, shipping more features, including a toggle for Claude response styles. More interestingly, however, is the Model Context Protocol, an open source standard for connecting data to LLM apps. Using the new desktop app, Claude can connect directly to GitHub, create a new repo, and make a PR through a simple integration. In the battle for mindshare, saving devs from the tedious task of writing multiple integrations is a smart move.
In news that will surprise … probably no one, Anthropic secured an additional $4B investment from Amazon. But the extra cash comes at the price of additional closeness. The company is now working with AWS on developing and optimizing Trainium, the company’s AI chip and accompanying software ecosystem. Despite discounted access programs and an aggressive marketing push, adoption remains slow. Amazon will go from being Anthropic’s primary cloud provider to also being its primary training partner. AWS customers will also get early access to new Claude models for finetuning purposes. Whatever else they might think, the likely departure of Lina Khan from the FTC can’t come soon enough for the world of GenAI partnerships.
In all this discussion of arms races, mindshare, and differentiation - do we have any sense of who’s winning? Menlo Ventures recently released a survey diving into enterprise LLM spend.
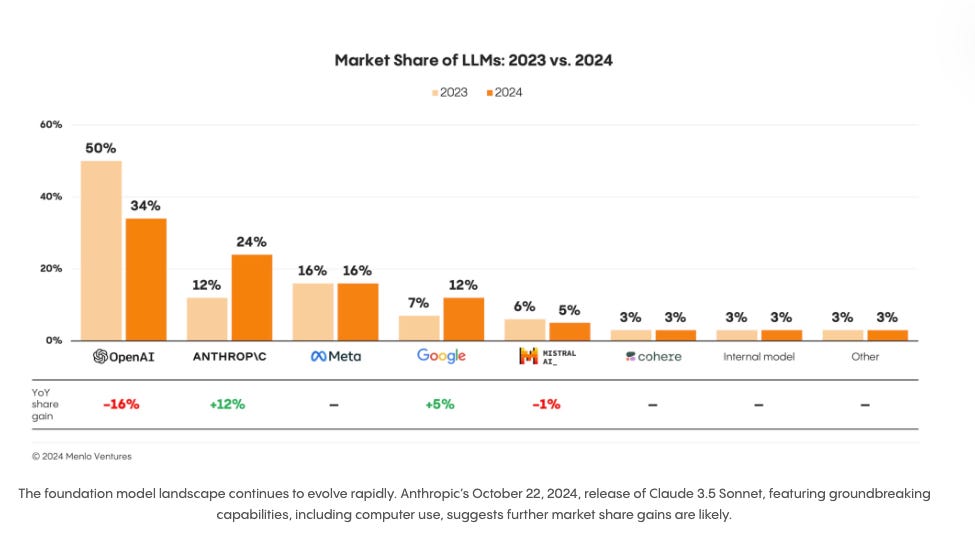
This isn’t entirely surprising: OpenAI remains in the lead, but increasingly no longer being the default choice as competition intensifies. Anthropic’s big push on price and features is bearing fruit. Llama is struggling with large enterprise adoption. And Gemini is fighting hard for dev users after a slow start.
While the LLM adoption race rages in the US, the Chinese frontier has been ablaze. Following on from a series of strong LLM and VLM releases, the reasoning models have started to land. DeepSeek was first out of the gate with R1-Lite-Preview, combining the team’s long-standing work on synthetic data and reasoning, to produce a model that rivals o1-preview-level performance on AIME & MATH benchmarks. Community reception, as far as we can tell, has been polished.

How is DeepSeek able to keep doing this? Dylan from SemiAnalysis reminds us that the team does have 50k Hopper NVIDIA GPUs, and isn’t whittling these models together on a few A100s in a shed. As Dylan puts it, “they are omega cracked on ML research and infra management but they aren’t doing it with that many fewer GPUs”.
For a glimpse into the thinking behind DeepSeek, check out this lengthy interview with CEO Liang Wenfeng. He makes the case for open models, argues that the chip embargo is hurting the business, and that DeepSeek is unusual in China for innovating rather than imitating.
DeepSeek isn’t the only Chinese team producing o1-like reasoning models.
After a run of strong (V)LLMs were released, QwQ’s reasoning model release should’ve been a big moment, especially given the very impressive benchmark performance they reported. But have they been a victim of the arms race and forced to release ahead of schedule? Chinese LLM power users have complained about elements of its output, while still acknowledging its impressive capabilities and potential to act as a serious o1 competitor.
Does this mean the gap has closed between US and Chinese labs? Our friend, former OpenAI exec Miles Brundage, reminds us that these models are being compared to o1-preview, not o1, so we aren’t seeing them compared against the best disclosed performance from a US lab. At the same time, Miles notes that “conversely, this wasn’t the best DeepSeek or Alibaba can ultimately do, either” and that “everyone actually doing this stuff at or near the frontier agrees there is plenty of gas left in the tank”. In fact, we tend to agree - Nathan and Eiso (Poolside’s CTO/co-founder) discuss how deep learning isn’t yet hitting a wall. Sorry to any Gary Marcus fans out there.
Crossing back to Europe, what’s going on at H Company? Regular Guide to AI readers will remember how the artists formerly known as Holistic raised a $220M seed, before losing three out of five of its co-founders. Since then, the company has shared its first progress update covering how Runner H 0.1, the agent they’ve built, powered by a proprietary VLM, squares up against the competition. H Company shows how they outperform Claude’s computer use agent across a number of tasks on the WebVoyager benchmark (largely around navigating to specific websites and performing certain tasks). Not everyone’s impressed.
🔬Research
TÜLU 3: Pushing Frontiers in Open Language Model Post-Training, Allen Institute for AI, University of Washington.
Presents TÜLU 3, a family of instruction-tuned language models based on the Llama 3.1 architecture. It follows a multi-stage training process that includes supervised fine-tuning (SFT), Direct Preference Optimization (DPO), and Reinforcement Learning with Verifiable Rewards (RLVR). The RLVR stage specifically trains the model on tasks that require verifiable correct answers, such as math problems and precise instruction following.
The models are designed to enhance core skills, including knowledge recall, reasoning, math, coding, instruction following, and safety. The training data includes both publicly available datasets (such as OpenAssistant and WildChat) and synthetically generated data, targeting specific skills. A key feature of TÜLU 3 is the careful decontamination of training data to ensure unbiased performance evaluation. The TÜLU 3 EVAL framework is used to assess the models across both development and unseen benchmark tasks.
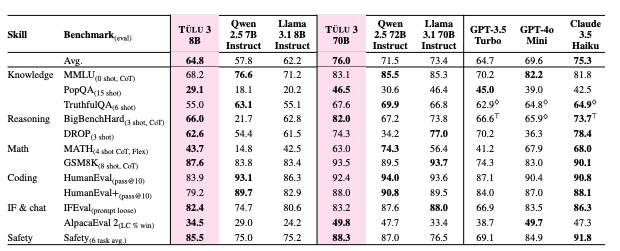
TÜLU 3 instruction-tuned models outperform other open-weight models, such as Llama 3.1 Instruct, Qwen 2.5, and Mistral-Instruct, and achieve competitive results with closed models like GPT-4o-mini and Claude 3.5 Haiku, particularly in tasks involving reasoning, safety, and precise instruction following. The TÜLU 3 family spans 8B to 70B parameters, and the team has made the model weights, training data, evaluation tools, and code publicly available.
Evaluating frontier AI R&D capabilities of language model agents against human experts, METR.
Introduces RE-Bench, a benchmark for evaluating AI systems' ability to automate AI research and development tasks. It features 7 challenging ML engineering tasks and compares performance between AI agents and 71 human expert attempts across 8-hour sessions. The environments cover areas like kernel optimization, model finetuning, and scaling law experiments.

Testing Claude 3.5 Sonnet and o1-preview models revealed that AI agents outperform humans in 2-hour time frames but show diminishing returns with longer durations. In contrast, humans demonstrate better improvement over extended periods, surpassing AI performance given 8+ hours. The study found AI agents can generate and test solutions much faster than humans and occasionally produce superior results, like developing more efficient GPU kernels.
However, the authors note significant limitations in extrapolating these results to real AI R&D automation capabilities. The benchmark's contained nature, clear objectives, and short timeframes don't capture the full complexity of real research projects that span months and involve multiple interacting workstreams.
Presents JAM (Joint Atomic Modeling), an AI system enabling fully de novo design of therapeutic antibodies with high specificity, functionality, and double-digit nanomolar affinities. JAM generates both single-domain (VHH) and full antibodies (scFv/mAb) that meet clinical development criteria, with iterative refinement improving binding success rates and affinities.
The researchers demonstrated JAM's capabilities against multiple targets, including the first fully computationally designed antibodies for challenging membrane proteins Claudin-4 and CXCR7. For SARS-CoV-2, JAM-designed antibodies achieved sub-nanomolar neutralization potency and drug-like developability profiles. Test-time computational introspection improved results, marking a novel application of compute scaling to protein design.
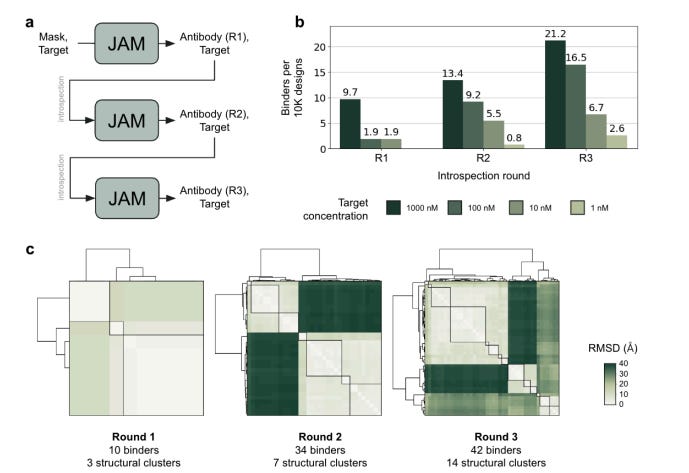
A key innovation was JAM's dual ability to design antibodies and soluble proxies for membrane protein targets, enabling efficient screening. The process from design to characterization requires less than 6 weeks, allowing parallel campaigns. Current limitations include humanness scores aligning more closely with chimeric than fully human antibodies. Nevertheless, JAM represents a major advance in computational antibody design, with the potential to transform therapeutic discovery workflows.
Also on our radar:
Vision Language Models are In-Context Value Learners, Google DeepMind, University of Pennsylvania, Stanford. Introduces Generative Value Learning (GVL), a novel method for task progress estimation using VLMs. Instead of looking at video frames in order, GVL shuffles them, forcing the model to focus on the content of each frame rather than relying on their sequence. GVL excels in zero-shot and few-shot learning across over 300 real-world robotic tasks, including complex bimanual manipulations, without task-specific training. Applications span dataset filtering, success detection, and reinforcement learning, demonstrating scalability and versatility in robotic learning contexts.
Open Catalyst experiments 2024 (OCx24), Meta. Describes the launch of OCx24, a collaborative project that bridges computational and experimental catalyst research through a dataset of over 600 materials tested for green hydrogen production and CO2 recycling. The project combines AI-powered simulations analyzing 19,000+ materials with real-world testing using automated synthesis techniques from partners at the University of Toronto and VSParticle. Results show promise in identifying low-cost alternatives to platinum-based catalysts for hydrogen evolution reactions.
Artificial Intelligence, Scientific Discovery, and Product Innovation, MIT. Examines how AI impacts scientific research by analyzing its introduction to materials discovery work at a large U.S. company's R&D lab. Finds that AI significantly boosted productivity, with scientists discovering 44% more materials and filing 39% more patents. But these gains were uneven - top scientists nearly doubled their output, while the bottom third saw minimal benefits. The differentiator was scientists' ability to evaluate AI's suggestions - those with strong judgment skills could effectively prioritize promising candidates, while others struggled with false positives.
The Dawn of GUI Agent: A Preliminary Case Study with Claude 3.5 Computer Use, National University of Singapore. Evaluates Claude 3.5 Computer Use, testing its capabilities across web browsing, office applications, and video games. The authors assess the model's performance across planning ability, action execution, and self-assessment. While scoring well on tasks like automated gaming and document editing, the model shows limitations in precise text selection, scrolling behavior, and accurately assessing task completion. The authors also introduce "Computer Use Out-of-the-Box" - an open-source framework to evaluate GUI automation models.
Inference Scaling 𝙵Laws: The Limits of LLM Resampling with Imperfect Verifiers, Princeton. Examines the limitations of inference scaling to improve the performance of weaker language models. Through experiments with coding tasks, the researchers found that while weaker models can match stronger models' performance on basic test cases through repeated sampling, they produce significantly more false positives - solutions that pass basic tests but fail comprehensive ones. The authors conclude there is a hard limit to weaker model performance, even with infinite sampling attempts.
InterPLM: Discovering Interpretable Features in Protein Language Models via Sparse Autoencoders, Stanford. Presents a new method for understanding how protein language models (PLMs) work internally by using sparse autoencoders (SAEs) to extract interpretable features and their hidden layers. The researchers identified thousands of biologically meaningful patterns in ESM-2's representations, significantly more than could be found by analyzing individual neurons directly. They demonstrate that these extracted features correspond to known protein properties like binding sites and structural motifs, can help identify missing annotations in protein databases, and can control the model's outputs in targeted ways.
💰Startups
🚀 Funding highlight reel
Anthropic, the frontier model lab, agreed a further $4B investment from Amazon.
Odyssey, building generative world-building models for film and gaming, raised an $18M Series A, led by EQT Ventures.
Cradle Bio, building AI-based protein-making software, raised a $73M Series B, led by IVP.
Enveda, the clinical stage drug discovery company focused on medicinal plants, raised a $130M Series C, led by Kinnevik and FPV Ventures.
Cyera, an AI-powered data security platform, raised a $300M Series D, led by Sapphire Ventures and Accel.
Enfabrica, developing networking solutions for compute infrastructure, raised a $115M Series C, led by Spark Capital.
Insider, the customer experience and engagement company, raised a $500M Series E, led by General Atlantic.
Lightning, the AI development platform, raised a $50M funding round, led by Cisco Investments, JP Morgan, K5 Global, and NVIDIA.
Moonvalley, building models for generative media, raised a $70M seed round, led by Khosla Ventures and General Catalyst.
Physical Intelligence, developing foundational software for robotics, raised a $400M Series A, led by Jeff Bezos, Lux, and Thrive Capital.
Robin AI, the AI legal start-up, raised a $25M Series B extension, led by Willett Advisors, the University of Cambridge, and PayPal Ventures.
Skydio, the drone company, raised a $170M Series E extension, led by Linse Capital.
Cogna, the AI-powered SaaS platform, raised a $15M Series A, led by Notion Capital.
Tessl, an AI-native development platform, raised a $100M Series A, led by Index Ventures.
Writer, a platform for building AI apps and workflows, raised a $200M Series C, co-led by Premji Invest, ICONIQ Growth, and Radical Ventures.
🤝 Exits
Alpaca, the AI-powered canvas for creatives, was acquired by Captions.
Datavolo, the data management company, was acquired by Snowflake.
Dazz, the security and remediation company, was acquired by Wiz for $450M.
Hazy, the synthetic data company, was acquired by SAS.
Signing off,
Nathan Benaich and Alex Chalmers on 1 December 2024
Air Street Capital | Twitter | LinkedIn | State of AI Report | RAAIS | Events
Air Street Capital invests in AI-first entrepreneurs from the very beginning of your company-building journey.
